Willkommen beim NETWAYS GitHub Update, der monatliche Überblick über unsere neuesten Releases.
Wenn du in Zukunft Updates direkt zu Release erhalten willst, folge uns einfach auf GitHub: https://github.com/NETWAYS/
Der Dezember ist je nach Branche eine besonders anstrengende oder eine eher ruhige Zeit. Bei unseren GitHub-Releases ging es in diesem Monat ruhiger zu, einen Release haben wir aber für dich:
check-smseagle v2.0.1
Nach langer Vorbereitungszeit endlich ein neues Release! Die Version 2.0.1 enthält nur einen kleinen Bugfix für das große 2.0.0 Release.
Changelog
- Support für (ausschließlich) Python 3
- Support für die neue API Version v2
- Support für CLI Optionen über Umgebungsvariablen
https://github.com/NETWAYS/check_smseagle/releases/tag/v2.0.1
Unsere Pläne für 2024
In 2023 war viel los auf unserem GitHub Account. Viele Issues wurden eröffnet und eine noch höhere Anzahl Pull Requests für unsere Projekte gestellt. Wir freuen uns, dass ein großer Teil davon bereits erfolgreich abgeschlossen und aufgenommen wurde.
Refaktorierung war für uns ein wichtiger Schwerpunkt des letzten Jahres und wir konnten einige interne Projekte endlich öffentlich zugänglich machen. So geht es hoffentlich auch 2024 weiter!
Außerdem planen wir Forks einiger beliebter Monitoring Check Plugins zu erstellen, die leider nicht mehr betreut werden. Auf weitere Informationen hierzu kannst du dich im Laufe des Jahres freuen!
Was wäre der Start in ein neues Jahr ohne einen kleinen Rückblick auf das vergangene Jahr? Hier unsere Highlights aus 2023:
icinga-installer Releases v1.0.0 – v1.2.7
Der icinga-installer – ein einfach zu benutzender Installer für Icinga ist im Februar 2023 in seiner v1.0.0 erschienen. Seitdem kamen einige Bugfixes und Anpassungen dazu, dass du nun einfach zu deiner funktionsfähigen Icinga Installation kommst.
https://github.com/NETWAYS/icinga-installer/releases/tag/v1.2.7
check-influxdb v0.1.0
Changelog
- Erster Release! Wir hoffen, Euch hilft das neue Plugin.
https://github.com/NETWAYS/check_influxdb/releases/tag/v0.1.0
support-collector Release v0.9.0
Changelog
- Hinzugefügt: Viele neue Kollektoren (Elastic Stack, Prometheus, Graylog, MongoDB, Foreman, diverse Webserver)
- Hinzugefügt: Neue CLI Option um sensitive Daten zu entfernen
- Hinzugefügt: Das Tool sammelt jetzt auch teilweise Logdateien ein
- Viele Abhängigkeiten unter der Haube aktualisiert
https://github.com/NETWAYS/support-collector/releases/tag/v0.9.0
ansible-role-ca Release v0.1.0
Wir bieten jetzt eine Ansible Rolle für die Verwaltung von CA und Zertifikaten an!
Die Rolle ist noch in einem sehr frühen Stadium, daher sind Pull Requests und allgemeines Feedback sehr Willkommen.
Changelog
- Initiales Release!
https://github.com/NETWAYS/ansible-role-ca/releases/tag/0.1.0

















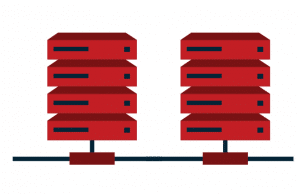 Bei einer Multi-Master-Replikation sind alle Server gleichwertig und replizieren Daten untereinander. Wenn ein Server ausfällt, übernehmen die verbleibenden Server seine Aufgaben. Doch hier wird es kniffelig. Wenn alle Server gleiches Stimmrecht haben, was passiert wenn mehrere Server an der selben Datei zeitgleich eine Änderung vornehmen?
Bei einer Multi-Master-Replikation sind alle Server gleichwertig und replizieren Daten untereinander. Wenn ein Server ausfällt, übernehmen die verbleibenden Server seine Aufgaben. Doch hier wird es kniffelig. Wenn alle Server gleiches Stimmrecht haben, was passiert wenn mehrere Server an der selben Datei zeitgleich eine Änderung vornehmen?

















