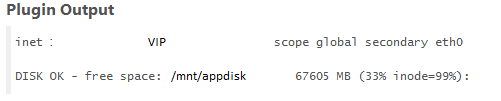
Neulich hatten wir bei einigen GitLab Updates auf die neueste Version das Problem, dass die Dienste nach dem Update zwar korrekt alle wieder gestartet wurden und daher unser alter Monitoring Check „Service: gitlab“ den Status „Gitlab OK: All services are running!“ zurückgeliefert hat, auch der Check „Service: http git.netways.de“ „HTTP OK: HTTP/1.1 200 OK“ geliefert hat, und daher hat ohne manuelle Prüfung niemand vermutet, dass im Hintergrund doch etwas schief gelaufen war (z.B. die Datenbank Migration während einem Update, oder ein vergessenes skip-XXX File im /etc/gitlab Verzeichnis).
Auch wenn man das Update direkt auf der command line ausgeführt hat, konnte man in der abschliessenden Meldung nicht sehen, ob noch alles o.k. ist.
Festgestellt hat man das dann erst, wenn man sich in der GitLab Admin Area unter „Health Check“ den Status angesehen hat.
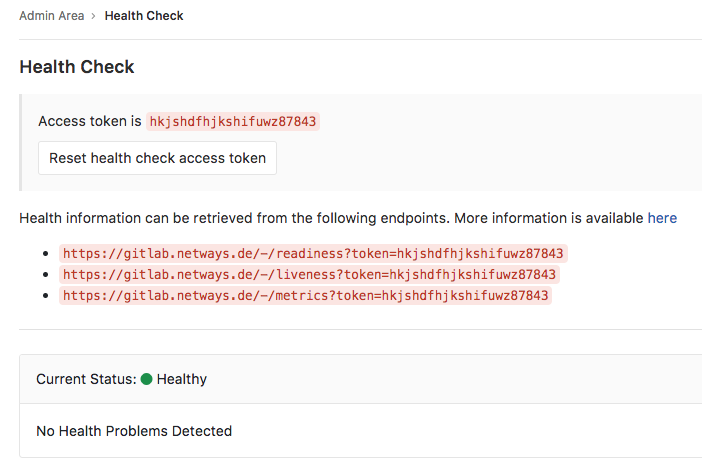
Unten ein Beispiel wie es aussieht, wenn alles i.O. ist (Zur Info: Die Beispiel URL und Token gibt es nicht):
D.h. ein neuer Check musste her, und den gibt es auch direkt bei GitLab zum Downloaden unter:
https://gitlab.com/6uellerBpanda/check_gitlab/blob/master/check_gitlab.rb
Der alte Check lief dabei direkt auf den einzelnen GitLab Hosts. Das war mit dem neuen Check allerdings ein Problem, weil er als Voraussetzung Ruby >2.3 hat, und wir z.B. noch einige Hosts unter Ubuntu Trusty betreiben.
Deshalb wird der neue Check direkt auf dem Monitoring Server (auch Ubuntu Trusty) ausgeführt, der zu diesem Zweck zusätzlich per rvm mit einem z.Zt. neuen Ruby 2.5.1 ausgestattet wurde, wobei im Ruby Skript das Shebang leider hardcoded eingetragen werden musste, weil es (zumindest unter Trusty) nicht anders funktioniert hatte (ohne grösseren Aufwand und vielen Änderungen an anderen Systemdateien):
#!/usr/local/rvm/rubies/ruby-2.5.1/bin/ruby
Nachdem die Token zum Zugriff im Bild oben seit einigen GitLab Versionen deprecated sind zugunsten einer IP Whitelist, hat das den Deploy des Checks zusätzlich erleichtert.
Der Aufruf des Checks sieht dann z.B. so aus:
root@icinga2-server:~# check_gitlab.rb -m health -s https://gitlab.netways.de -k OK - Gitlab probes are in healthy state
Damit das dann auch funktioniert, muss auf der entfernten GitLab Instanz noch die IP Whitelist unter /etc/gitlab/gitlab.rb eingetragen werden:
gitlab_rails['monitoring_whitelist'] = ['127.0.0.1/8','10.XX.XX.XX/24']
Am besten checkt man natürlich nur über ein internes Netz, wie oben im Beispiel angegeben.
Das ganze kann man auch über ein GitLab Puppet Modul realisieren, indem man die Whitelist über Hiera oder Foreman verteilt:
Beispiel Hierarchie im Foreman:
gitlab:
gitlab_rails:
monitoring_whitelist:
- 127.0.0.1/8
- 10.XX.XX.XX/24