In 2022 wurde die Icinga DB erfolgreich veröffentlicht und für die produktive Nutzung freigegeben. Wir haben hierzu bereits ein Webinar mit dem Titel „Was ist die Icinga DB?“ durchführt, in welchem wir die Architektur im Detail erläutert haben.
Dabei sind wir auf
- das neue Datenbank-Backend
- den Redis als Cache
- und die Kommunikation zwischen Core und Web
eingegangen.
Der Vorteil der Icinga DB
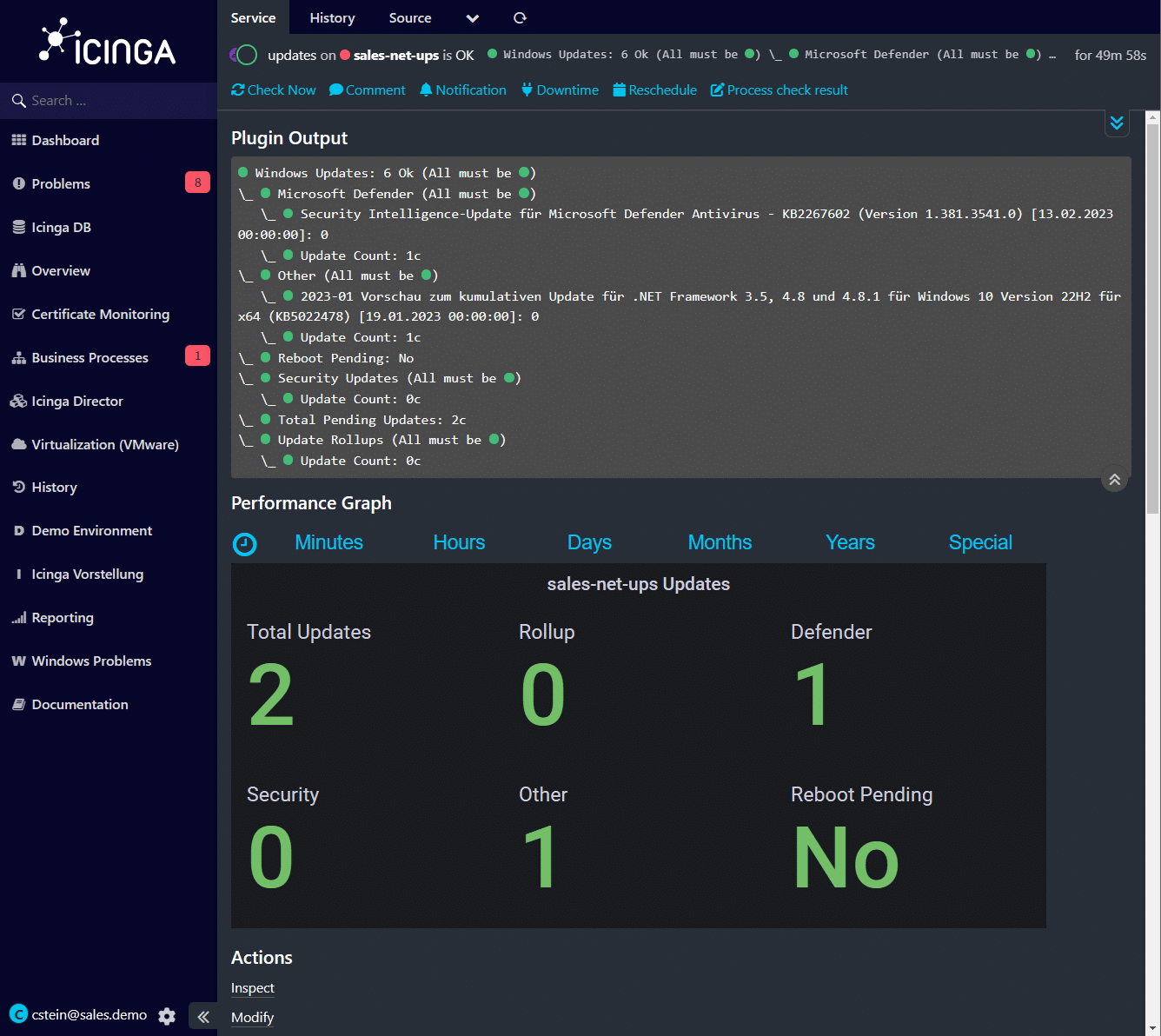
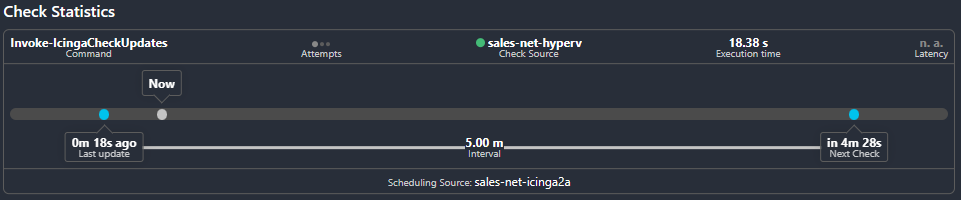
Die Icinga DB bietet neben einer vollständig neuen Architektur ein neues Webfrontend, welches völlig neu gestaltet ist. Damit sind einzelne Elemente nun deutlich besser ersichtlich und erlauben einen noch schnelleren Überblick, wie beispielsweise der Status der aktuellen Check-Ausführung ist, in welchem Intervall geprüft und wann dieser ausgeführt wird.
Installation und Konfiguration
Eine ausführliche Anleitung für die Installation findet man in der offiziellen Dokumentation auf icinga.com. Wir möchten hierfür jedoch einen Schritt weitergehen und werden unsere aktuelle Demo-Umgebung, welche wir in einer Icinga Webinar-Reihe aufgebaut haben, in einem Webinar Live auf die Icinga DB umstellen.
Das Webinar findet am
statt. Hierfür könnt Ihr einfach unseren YouTube-Kanal abonnieren und einen Reminder für das Icinga DB Webinar setzen.
Wir freuen uns auf eure Teilnahme! Wenn Ihr im Vorfeld Unterstützung bei der Migration auf die Icinga DB benötigt, nehmt doch gerne Kontakt mit uns auf. Wir bieten euch gerne Dienstleistungen und Beratungen dazu an.



 Wenn man allerdings einen EE Server parallel hochzieht, um dann auf diesen zu migrieren, so kommen ein paar mehr Schritte hinzu.
Wenn man allerdings einen EE Server parallel hochzieht, um dann auf diesen zu migrieren, so kommen ein paar mehr Schritte hinzu.
 For some time it has become clear that
For some time it has become clear that 















