Der Lennart sagt mir ja immer, ich soll nicht über ungelegte Eier sprechen, aber momentan fasziniert mit das Thema einfach zu viel, als dass ich nicht drüber was schreiben könnte. Dass ich gern mit dem Elastic Stack arbeite, sollten auch weniger aufmerksamere Leser schon mitbekommen haben, aber mit Ansible hab‘ ich mich bisher recht zurückgehalten. Da ich aber eigentlich beides ganz gern mag, dachte ich mir, ich verbinde es mal.
Mit Ansible ist es wie bei den meisten Configmanagementsystemen: Man fängt mal an, was zu bauen, findet’s gut, lernt was dazu, findet’s nicht mehr gut, baut’s neu, findet’s richtig gut, lernt dazu, findet’s eher mies, baut’s neu, ein Loch ist Eimer, lieber Reinhard, lieber Reinhard.

Deshalb dachte ich, ich bemüh‘ mich jetzt mal, eine Rolle für Logstash zu bauen, die man auch wirklich guten Gewissens so rausgeben kann. Falls was nicht so schön ist, gibt’s dann wenigstens die ganzen lieben Leute da draußen, die Pull Requests machen *wink*. Hier also der aktuelle Stand unserer Ansible Rolle für Logstash.
Ich geb‘ ja zu, es ist noch eine recht frühe Version, aber sie ist immerhin so gebaut, dass sie umfassend konfigurierbar ist und auch der Linter von ansible-galaxy beschwert sich dabei nicht mehr. Anders ausgedrückt: Sie kann noch nicht extrem viel, aber das, was sie kann, kann sie ziemlich gut, meiner Meinung nach.
![]()
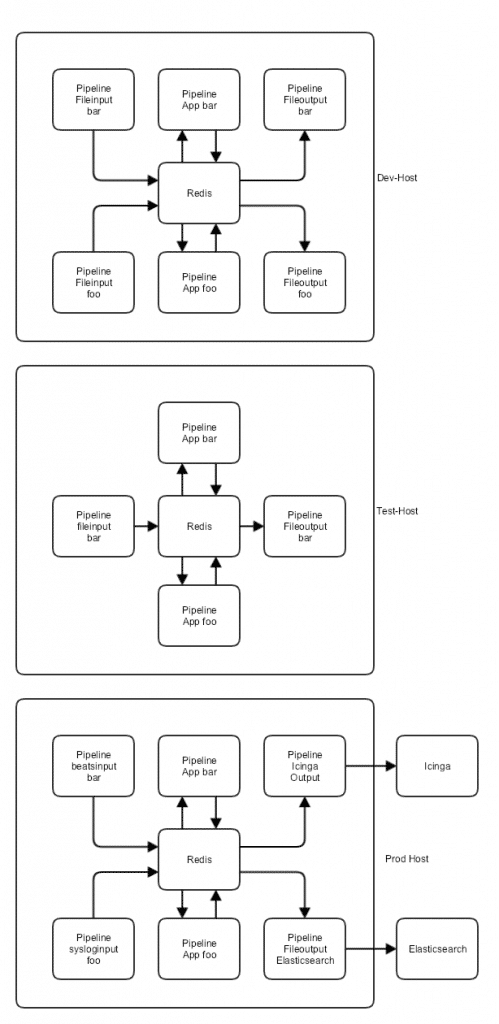
Ein schönes Feature, das mir besonders zusagt ist, dass sie einen dazu bringt, die Konfiguration der einzelnen Pipelines in einem Git Repository zu pflegen und zwar ein Repository pro Pipeline. Damit kann man die Rolle schön in Kombination mit unserer Logstash Pipeline für Icinga Logs nutzen. Ein paar Beispielpipelines, die aktuell nur Logs von A nach B schaufeln, habe ich in meinen persönlichen GitHub Account gelegt, von wo sie auch als Beispiele bei der Installation verwendet werden können. Ob das so bleibt, entscheidet sich noch, auf jeden Fall soll die Pipeline mit minimaler oder keiner Konfiguration zumindest mal Basisfunktionalität in Logstash herstellen. Ganz so, wie Elastic das geplant hat – ein einfacher Einstieg für Neulinge. Aber auch ausgefeiltere Setups sind damit möglich.
Besonders gut funktioniert die Rolle übrigens gemeinsam mit einer Rolle für Redis, aber das ist alles in der Readme beschrieben.
Weitere Rollen zum Rest vom Stack werden wohl noch kommen und die Logstash Rolle kann auch noch einiges an zusätzlichen Konfigoptionen brauchen. Lasst Euch also nicht aufhalten, Issues aufzumachen oder Pullrequests zu schicken.


 Wie alle guten Weine brauch auch manchmal ein Erlebnis eine Weile um zu einer guten Erfahrung zu reifen. So war es für mich mit der Elastic{ON} 2018 und passend zum Feiertag hole ich für euch nun unsere Review aus dem Keller, öffne die Flasche und wir schauen gemeinsam zurück auf das Event.
Wie alle guten Weine brauch auch manchmal ein Erlebnis eine Weile um zu einer guten Erfahrung zu reifen. So war es für mich mit der Elastic{ON} 2018 und passend zum Feiertag hole ich für euch nun unsere Review aus dem Keller, öffne die Flasche und wir schauen gemeinsam zurück auf das Event.



 Am zweiten Konferenztag waren wir überwiegend gemeinsam Unterwegs und durften uns über die Überklimatisierung der Räume erfreuen, welche für Eiszeiten sorgte. An diesem Tag nahmen Thomas und ich an einer Videostory teil, welche bis jetzt wohl noch nicht veröffentlich ist.
Am zweiten Konferenztag waren wir überwiegend gemeinsam Unterwegs und durften uns über die Überklimatisierung der Räume erfreuen, welche für Eiszeiten sorgte. An diesem Tag nahmen Thomas und ich an einer Videostory teil, welche bis jetzt wohl noch nicht veröffentlich ist.




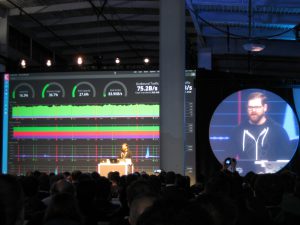 „Machine Learning“ ein Kibana Feature, das aus „Prelert“ entstanden ist, nur für Nutzer von X-Pack erhältlich sein. Ob „Canvas“, ein Feature, mit dem Reports und Präsentationen aus Kibana heraus erstellt werden können, frei verfügbar sein wird, wird noch entschieden. Auf jeden Fall würde das vielen Usern sehr weiterhelfen, nach dem, was wir an Nachfragen erhalten.
„Machine Learning“ ein Kibana Feature, das aus „Prelert“ entstanden ist, nur für Nutzer von X-Pack erhältlich sein. Ob „Canvas“, ein Feature, mit dem Reports und Präsentationen aus Kibana heraus erstellt werden können, frei verfügbar sein wird, wird noch entschieden. Auf jeden Fall würde das vielen Usern sehr weiterhelfen, nach dem, was wir an Nachfragen erhalten.
















