Wenn man als Open Source Dienstleister langfristig Erfolg haben will, muss man mit der Zeit gehen und die eigene Arbeitsweise in regelmäßigen Abständen hinterfragen. War bis vor einigen Jahren das Erarbeiten eines Konzepts zur Veranschaulichung einer möglichen Umsetzung der Quasi-Standard im IT-Consulting, gibt es mittlerweile valide Alternativen. Besonders beliebt und erprobt ist das Proof of Concept
Konzept
Jedes Projekt steht bzw. fällt mit dem zugrundeliegenden Konzept. Erst mit diesem können wir für dichals unsere:n Kund:in ein spezifisches Angebot mit genauen Arbeitspaketen und Abfolgen erstellen.
Um ein gutes Grobkonzept zu erstellen, sammeln wir Informationen wie Ziele, Wünsche oder bestehende Probleme für die neue Umgebung. Dazu sammeln wir mit dirzusammen Eckdaten und definieren Ziele in einem gemeinsamen Onboarding Workshop.
Was ist das Ziel der neuen Umgebung?
- Benachrichtigen im Fehlerfall?
- Metriken sammeln und Trends erkennen?
- Automatisierte Installation?
- SLAs für Kunden bereitstellen?
Wer ist die Zielgruppe?
- Kollegen aus dem Nachbarbüro
- Kund:innen mit SLA Vereinbarungen
- Zentrale Ansicht für ein Incident Management Team
- Verteilte Teams die Tool as a Service nutzen
Handelt es sich um eine Migration von Icinga oder einem anderen Tool, ist es besonders wichtig Probleme in der aktuellen IT-Umgebung zu identifizieren. Dazu zählen Ausfälle des Systems, Performance Probleme, Schwierigkeiten bei der Handhabung, beim Update oder bei der Erweiterung der Umgebung.
Mit diesen Informationen wird das bereits angesprochene Grobkonzept erstellt. Es enthält eine Analyse des aktuellen Stands, Herausforderungen mit der bestehenden Umgebung und die gemeinsam definierten Ziele. Um das Projekt für dichtransparent und mit klaren Arbeitspaketen zu gestalten, werden alle definierten Tools und Lösungsansätze umfangreich beschrieben.
Um dir einen Überblick über den zeitlichen Rahmen des Projekts zu geben, kalkulieren wir um NETWAYS IT Consulting den zeitlichen Aufwand der definierten Arbeitspakete.
Proof Of Concept
Ein Proof of Concept (POC) hilft bei der Projektplanung dabei eine Lösung zu simulieren, Probleme in der Benutzung zu finden oder technische Möglichkeiten aufzuzeigen. Bevor ein POC umgesetzt wird, muss festgelegt werden, was genau simuliert oder dargestellt werden soll. Diese Ziele und ein zeitlicher Rahmen werden in einem gemeinsamen Termin zwischen dirund deinem persönlichen Consultant besprochen und festgelegt.
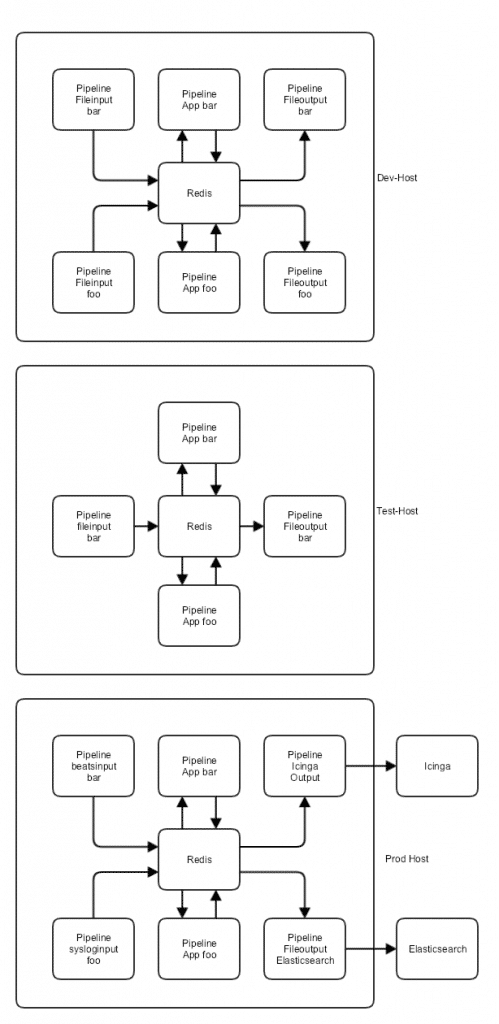
Im Anschluss wird die Vorgehensweise des Proof of Concept festgelegt. Im Icinga Umfeld kann zum Beispiel eine in deiner Infrastruktur gestartete Virtuelle Maschine aufgesetzt werden. Diese kann vom dir und deinem Team umfangreich getestet und weiteren Kolleg:innen bzw. dem Management vorgeführt werden. Des Weiteren kann können wir individuelle Lösungen auch in einer lokalen Entwicklungsumgebung testen, falls Freigaben oder Vorbereitungen kurzfristig nicht umgesetzt werden können.
Im Falle von Icinga können meine Kolleg:innen oder ich mit Hilfe von Automatisierungslösungen wie Ansible oder Puppet schnell eine Umgebung aufsetzen. Dadurch sparen wir uns wertvolle Zeit, um gemeinsam weitere Lösungen für die individuellen Herausforderungen Deines Unternehmens zu evaluieren.
Konzept vs POC
Je nach Anforderungen und Projekt ist ein Konzept oder ein POC sinnvoll. Grundsätzlich kann ein Proof of Concept Deine Wünsche schneller abbilden, eine Umgebung visualisieren sowie Vorteile und Nachteile einer Lösung hervorheben. Ein Konzept hingegen ist lediglich die theoretische Planung eines Projekts und kann wenig über die Funktionalität der Lösung aussagen. Daher ist hier die Expertise und Erfahrung des Consultants wichtig.
Bei größeren Projekten mit neuen Herausforderungen werden häufig beide Varianten gemeinsam eingesetzt, um die Komplexität des Projekts bestmöglich abzubilden. Ein POC, welches dir und deinem Team die spezielle Lösung visuell demonstrieren und simulieren kann. Im Anschluss wird die endgültige Lösung in einem Konzept festgehalten um einen zeitlichen Projektrahmen zu schaffen. Zudem werden für das Projekt Voraussetzungen, Arbeitspakete und Sizing definiert.
Die Umsetzung des Projekts ist bei allen Unternehmen individuell gestaltet. Mein Team und ich können, wenn ein Zugriff gegeben ist, die Umgebung kundenunabhängig aufbauen und im Anschluss eine technische Dokumentation der Arbeitsschritte bzw. der Umgebung liefern. Hierbei arbeiten deine NETWAYS Consultants mit einer Vielzahl von Tools wie Citrix, AnyDesk oder VPN.
In anderen Fällen ist kein direkter Zugriff auf den Server vorhanden oder du willst direkt bei der Umsetzung dabei sein, um gleichzeitig vom Workshop als direkte Schulung zu profitieren. Dabei werden Fragen zu Handling und Aufbau direkt beantwortet.
Wissen für alle
Nach erfolgreicher Umsetzung des Projekts muss schließlich noch ein Wissenstransfer stattfinden. Dieser ist je nach Projekt, Tool und Umgebung verschieden. Nach Projekten in enger Zusammenarbeit sind während des Workshops bereits viele grundsätzliche Fragen geklärt und meist ist der Kunde im Handling mit der Umgebung sicher. In solchen Fällen ist eine technische Dokumentation des Projekts ausreichend.
Falls ein Projekt unabhängig vom Kunden durchgeführt wurde, sollte idealerweise noch ein Wissenstransfer in Form eines extra Workshops oder gar einer Schulung stattfinden. Abhängig von der Anzahl der Mitarbeiter, welche die Umgebung bedienen, ist es sinnvoll eine Schulung für das gesamte Team durchzuführen. Bei einer kleineren Anzahl an Benutzern kann bereits ein Hands-On Workshops von ein paar Stunden ausreichen, um dem Kunden den Umgang und die Konfiguration der neuen Umgebung nahe zu bringen.
Falls du nun Neugierig geworden bist und aktuell sowieso auf der Suche nach einem erfahrenen Open Source IT-Dienstleister mit Herz bist, dann melde dich gerne bei uns! Ich und meine Kolleg:innen führen gerne eine individuelle Betrachtung zu deiner IT-Umgebung und ihren Anforderungen durch. Im Rahmen eines ersten Consultingtermins sprechen wir gemeinsam gerne über deine Vorstellungen und Wünsche für deine IT-Infrastruktur. Ich bin mir sicher, gemeinsam finden wir die beste Lösung!

 Wie gerade schon erwähnt, hatten wir zuvor eine Linux-Schulung. Diese war unsere erste Schulung und sollte Grundlagen für die kommenden Jahre schaffen. Zuerst ging es um die Basics: Was ist Linux überhaupt? Wie bedient man Linux? Danach haben wir gelernt: Was ist ein Paketmanager, wie funktioniert ein Dateisystem, wofür benötigt man eine SSH-Verbindung. Natürlich haben wir noch viel mehr gemacht, aber dies würde einen eigenen Blogpost benötigen.
Wie gerade schon erwähnt, hatten wir zuvor eine Linux-Schulung. Diese war unsere erste Schulung und sollte Grundlagen für die kommenden Jahre schaffen. Zuerst ging es um die Basics: Was ist Linux überhaupt? Wie bedient man Linux? Danach haben wir gelernt: Was ist ein Paketmanager, wie funktioniert ein Dateisystem, wofür benötigt man eine SSH-Verbindung. Natürlich haben wir noch viel mehr gemacht, aber dies würde einen eigenen Blogpost benötigen.