Zugegeben, vor dem konkreten Problem, eine fast 2 TB große Datei von einem System zu transportieren, auf das man nur über mehrere Hops Zugriff hat, steht man nicht jeden Tag. Aber wenn doch, dann bietet eine ganze Sammlung an Tools eine gemeinsame Lösung an.
Mit „mehrere Hops“ ist gemeint, dass es nicht möglich ist, mit den üblichen Bordmitteln wie scp oder rsync Daten zu kopieren. Ein Beispiel könnte ein Citrix-Zugang mit PuTTy sein, der zwar Shell-Zugriff erlaubt, aber kein Kopieren. Im konkreten Fall „durften“ die Daten natürlich kopiert werden, es war schlicht nur technisch nicht „möglich“. Der Host, auf dem die Daten lagen, hatte Zugriff auf Websites im Internet durfte aber keine anderen Protokolle „nach draussen“ benutzen.
Zerhacken und Zerteilen um riesige Datenmengen transportieren zu können
Zwar ist es heutzutage eigentlich problemlos möglich, auch riesige Datenmengen von A nach B zu kopieren. Da wir hier aber von einem nicht unerheblichen Zeitraum sprechen, den die Kopie braucht und ein kurzer Abbruch wertvolle Zeit gekostet hätte, war der Ansatz erstmal folgender:
- Die Daten so klein komprimieren wie es sinnvoll ist (hier mit
bzip2) - Die Daten klein hacken (mit
split) - Die einzelnen Stücke dann hochladen
- Beim Empfänger zusammensetzen und entpacken
Das lässt sich ganz gut per Shell realisieren.
nohup time tar cjvf testdb.tar.bz ../backups/full/ & split -b5000000000 testdb.tar.bz
Die Datenbank bestand dabei aus einigen sehr kleinen Dateien und einigen, die etliche GB und teilweise sogar über 1 TB groß waren. Es zahlte sich also nicht aus, die Dateien einzeln zu kopieren.
nohuplässt den Befehl weiterlaufen, auch wenn die Verbindung abbricht und schreibt den Output nach nohup.outtimegibt ab, wie lang das Komprimieren braucht. Weil ich einfach ein neugieriger Mensch bintarmit-jkomprimiert die Dateien mit bzip2 statt gzip was in vielen Fällen zwar länger dauert aber deutlich kleinere Dateien hervorbringtsplithackt eiskalt die Dateien in kleine Teile. In diesem Fall jeweils 5 GB groß. Dabei hat der Befehl noch einige Optionen um einem das Leben leichter zu machen. Es zahlt sich aus, da etwas mehr nachzustöbern als ich das damals gemacht hab
Somit hat man dann eine große Anzahl „ausreichend kleiner“ Dateien. Mit tail -f nohup.out kann man beobachten, was sich gerade tut. Das geht auch, wenn disconnected wurde. Alternativ kann man auch screen oder tmux nehmen. Da diese Tools aber Probleme mit manchen remote Verbindungen machen und nicht immer zur Verfügung stehen, bleib‘ ich persönlich lieber bei nohup.
Übrigens sollte man nicht unbedingt an die maximale Obergrenze des Uploads gehen. Beim ersten Versuch hab‘ ich das getan und die Daten wurden teilweise von NextCloud verworfen. Warum, hab‘ ich nicht mehr versucht herauszufinden, weil es bei der Methode eigentlich egal ist, ob man wenige große oder sehr viele sehr kleine Dateien nimmt. 5 GB haben aber gut funktioniert.
Der Transporter
Zugegeben, ich hatte den Vorteil, eine NextCloud Instanz nutzen zu können, die noch dazu genug Platz bot. Der Trick funktioniert bis hier her aber natürlich auch mit jedem anderen Übertragungsweg. Auch wenn man die Dateien ggf. kleiner hacken muss.
Für den weiteren Schritt baut man sich ein kleines Script.
#!/bin/bash for i in $(ls x*) do curl -T $i -u transportuser:$MYPASSWORD done
Auch dazu ein paar Erklärungen.
ls x*gibt alle Dateien aus, die split erstellt hat. Ohne weitere Optionen startet der Name aller zerlegten Dateien mitx- In der NextCloud wird im Home von User transportuser der Ordner testdb angelegt
- curl nutzt WebDAV um die einzelnen Schnippsel hochzuladen
- Der User
transportuserwurde dafür extra angelegt und der Ordnertestdbden eigentlichen Empfängern freigegeben. Das erleichtert das Management und vor allem das Passworthandling - Das Passwort kommt im nächsten Schritt
Tatsächlich riesige Datenmengen transportieren
Das Script hat noch eine Einschränkung. Da es auf einem „fremden“ System liegt, möchte man darin natürlich nicht das Passwort eines NextCloud Users hinterlegen. Wir haben einige Möglichkeiten ausprobiert und dabei auch bedacht, dass man es evtl. aus der Shell-History oder der Prozessliste auslesen könnte. Das beste, das wir bisher gefunden haben ist eine Umgebungsvariable, die nicht in der History landet.
export MYPASSWORD=mysupersecret nohup time ./thetransporter.sh
Und wieder Erläuterungen.
- Die erste Zeile ist um eine Stelle eingerückt. Das verhindert (üblicherweise!) dass sie in die Shell History aufgenommen wird. Bevor man sich darauf verlässt, sollte man das unbedingt testen!
- Die zweite Zeile ruft schlicht das Script von oben auf, wo die Umgebungsvariable genutzt wird
Andere Lösungen, wie eine interaktive Angabe beissen sich sich mit nohup.
Ganz unabhängig davon, ob das Passwort hier sicher genug war oder nicht, schadet ein Wechsel des Passworts direkt im Anschluss sicher nicht. Hat man sich einen eigenen User für den Transport angelegt, kann man ihn auch einfach wieder entfernen.
Die Auflösung
Hat man die Daten so in die NextCloud gepushed, kann man sie einfach mit dem NextCloud Client auf ein eigenes Gerät synchronisieren lassen. Tip: Man kann im Client angeben, welche Ordner synchronisiert werden sollen und welche nicht, falls man mehrere Geräte angeschlossen hat.
Um die Daten wieder zusammenzubauen reicht ein schlichtes cat.
cat x* > testdb.tar.bz2 tar xvf testdb.tar.bz2
Und was? Ja, Erläuterungen.
splitbenennt die Dateien so, dass die alphabetische Sortierung voncatsie wieder richtig zusammenbauttarist inzwischen so schlau, dass man die Kompressionsmethode nicht mehr angeben muss. Schadet zwar nicht, sieht aber irgendwie cooler aus so
Besonders charmant finde ich daran, dass es den Tools völlig wurscht ist, was in den Dateien drin ist. Ob das Klartext, binaries oder was auch immer sind. Sie tun ja nichts mit dem Inhalt, zerhacken sie nur und stückeln sie zusammen.
Wer uns gern an solchen Lösungen kiefeln und werkeln sehen möchte, schliesst am besten gleich einen Support-Vertrag bei uns ab.

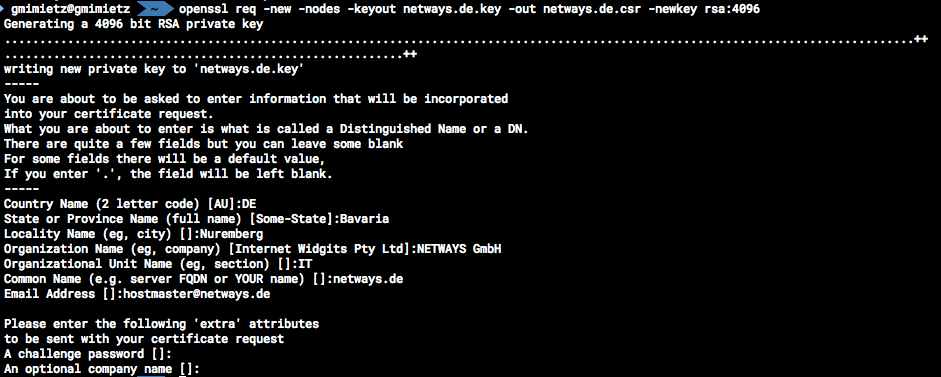 Hier wird nach dem Land, dem Staat, der Stadt, der Firma, der Abteilung, der zu sichernden Domain und der Kontaktmailadresse gefragt. Eingaben können auch leergelassen werden und mit der Eingabetaste übersprungen werden (ACHTUNG: Defaultwerte (sofern vorhanden) aus den eckigen Klammern werden übernommen).
Hier wird nach dem Land, dem Staat, der Stadt, der Firma, der Abteilung, der zu sichernden Domain und der Kontaktmailadresse gefragt. Eingaben können auch leergelassen werden und mit der Eingabetaste übersprungen werden (ACHTUNG: Defaultwerte (sofern vorhanden) aus den eckigen Klammern werden übernommen).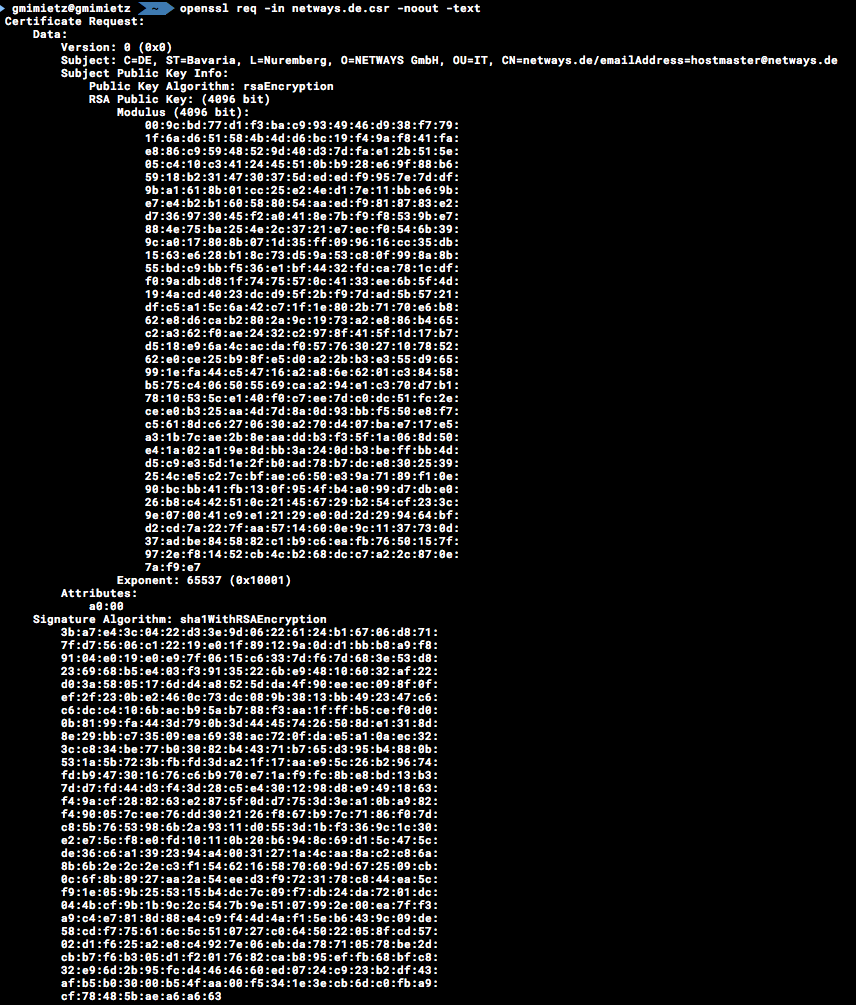 Abschließend kontrollieren wir das Keyfile noch (zumindest, ob es so in der Art aussieht).
Abschließend kontrollieren wir das Keyfile noch (zumindest, ob es so in der Art aussieht).

 Für mich privat betreibe ich momentan 3 eigene Server, für
Für mich privat betreibe ich momentan 3 eigene Server, für 


















