Für viele Anwender ist die einfache Skalierbarkeit und Flexibilität von Anwendungen im Cluster der Hauptgrund für einen Umstieg auf Kubernetes. Doch auch hier geschieht nichts (oder nur sehr wenig) „magisch“ und von allein. Anwendungen müssen bereits zum Zeitpunkt der Entwicklung in Hinblick auf diese gewünschte Flexibilität gebaut und die Deployments entsprechend konfiguriert werden. Natürlich spielt die Infrastruktur, auf der K8s selbst läuft, ebenfalls eine wichtige Rolle. Aber bevor wir direkt zu tief einsteigen, fangen wir doch erstmal mit den Basics an und klären zunächst ein paar Begrifflichkeiten.
Bei Deployments handelt es sich um eine von Kubernetes definierte Abstraktion von zu betreibenden Anwendungen. Anstelle einer konkreten Konfiguration für genau einen Pod wird ein sogenanntes Template definiert, quasi eine Vorlage für eine beliebige Anzahl an zu betreibenden Pods. Durch diese Abstraktion können mehrere Pods des gleichen Deployments gebündelt betrachtet und verwaltet werden, was mehrere Vorteile mit sich bringt – unter anderem eine einfachere Skalierung.
Willst du deine Anwendungen nun skalieren, ist es wichtig den Unterschied zwischen horizontaler Skalierung und vertikaler Skalierung (Scaling out vs. Scaling up) zu verstehen.
Horizontale Skalierung beschreibt das Hinzufügen neuer Pods (oder Nodes, auf Clusterlevel) zum Cluster, um beispielsweise Anfragespitzen eines Webshops o.Ä. zu bewältigen. Vertikale Skalierung hingegen bezeichnet das Hinzufügen von mehr Ressourcen zu bestehenden Pods oder Nodes, beispielsweise in Form von mehr vCPUs oder Arbeitsspeicher.
Nachdem wir jetzt die wichtigsten Begriffe geklärt haben und (hoffentlich) auf dem gleichen Wissensstand sind, steigen wir ordentlich in das Thema Skalierung auf K8s ein!
Skalierung von Deployments
Wenn du und dein Team den Plan verfolgen Anwendungen auf Kubernetes skalieren, hast du dafür mehrere Möglichkeiten. Zum einen die grundlegende Unterscheidung zwischen horizontalem und vertikalem Scaling, zum anderen die Frage, ob und wie diese Skalierung automatisiert werden kann. Für Workload-Skalierung wird meistens horizontales Scaling genutzt. Wie du bereits weißt, ist das gleichbedeutend mit dem Hinzufügen neuer Pods zu dem bestehenden Deployment. Das kannst du theoretisch manuell umsetzen, bspw. mittels eines kubectl Befehls:
kubectl scale --replicas=5 deployment/application-a
In diesem Beispiel weist man Kubernetes‘ API an, das Deployment application-a auf 5 Pods zu skalieren. K8s kümmert sich dann automatisch um den Rest. Optional können bei Verwendung von kubectl auch Voraussetzungen mitgegeben werden, die für eine Skalierung notwendig sind, etwa die Anzahl momentan laufender Pods oder eine erwartete Versionsnummer. Treffen die Voraussetzungen nicht zu, wird auch keine Skalierung vorgenommen.
Du merkst, der manuelle Ansatz funktioniert relativ simpel. Er bringt aber auch einige Schwierigkeiten mit sich! So müssen bestehende Deployments kontinuierlich auf die Anzahl ihrer Repliken geprüft werden. Denn nach einer Skalierung der Deployments auf mehr Repliken z. B. aufgrund von hoher Last auf der Anwendung, kann diese nicht automatisch wieder herunterskaliert werden. Hier lassen sich also sehr einfach Geld und Clusterressourcen verschwenden.
Des Weiteren muss jede Skalierung, egal in welche Richtung, von einem Clusternutzer mit entsprechenden Rechten vorgenommen werden. Und ab einer gewissen Anzahl an Skalierungsanfragen ist diese Art zu arbeiten einfach nicht mehr praktikabel. Es benötigt also eine Form der Automatisierung.
Voraussetzungen für automatisierte Skalierung
Damit du eine automatisierte Skalierung von Deployments aber überhaupt durchführen kannst, ist ein entsprechender Controller im Cluster notwendig. Dieser muss zum Einen die zu definierenden Anforderungen an die Deployments erkennen und (re-)evaluieren, und zum anderen die daraus resultierenden Skalierungen vornehmen. Das Kubernetes-Projekt bietet hier sowohl für horizontales Autoscaling als auch für vertikales Autoscaling einen entsprechenden Controller:
Egal für welche Vorgehensweise du dich entscheidest, die Controller übernehmen die gleiche Aufgabe. Sie prüfen in einem zu definierenden Intervall (standardmäßig alle 15 Sekunden), ob die festgelegten Grenzwerte für ein Auf- oder Herunterskalieren des betroffenen Deployments über- bzw. unterboten werden und passen die Anzahl an Repliken entsprechend an.
Für die Konfiguration dieser Grenzwerte gibt es eine eigene API-Ressource namens HorizontalPodAutoscaler.
Eine weitere Voraussetzung der automatisierten Skalierung ist die Installation des sogenannten Metricsservers. Er übernimmt die Aufgabe, deine Pod- und Containermetriken innerhalb des Clusters zu aggregieren und via Kubernetes-API für beliebige Drittanwendungen bereitzustellen – zum Beispiel für unsere Autoscaler.
Einrichtung automatisierter Skalierung
An diesem Punkt habe ich dir hoffentlich die Vorteile einer automatisierten Skalierung näherbringen können und du kannst es kaum abwarten, selbst damit loszulegen. Dafür kannst du dich (wie so oft) zwischen zwei Möglichkeiten entscheiden: Imperativ durch einen kubectl Befehl oder deklarativ durch ein Kubernetes-Manifest. Um dir beide Varianten besser zu veranschaulichen, habe ich Beispiele für den HorizontalPodAutoscaler eines Deployments nginx geschrieben.
Imperativ
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
Deklarativ
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx
namespace: default
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
Beide Varianten erstellen ein HorizontalPodAutoscaler Objekt, dass das Deployment nginx bei durchschnittlicher Auslastung von 50% hochskaliert bzw. bei 0% in einen Bereich zwischen 1-10 Pods herunterskaliert. Auf diese Weise lassen sich Kubernetes Deployments automatisch horizontal skalieren, die Grenzwerte sind dabei seit API-Version 2 des HorizontalPodAutoscalers sehr flexibel konfigurierbar.
Anstatt lediglich auf ein von der Kubernetes-Metrics-API bereitgestelltes Attribut zu schauen (CPU-Last/Memory) können mehrere Attribute kombiniert werden oder sogar externe Messwerte verglichen werden, beispielsweise resultierend aus einer Überwachung mittels Prometheus. Außerdem können statt der Metriken von Pods die einzelnen Metriken für Container als Basis des Autoscalings genutzt werden.
Und auch ansonsten bietet die API-Definition des HorizontalPodAutoScalers eine Bandbreite an konfigurierbarem Verhalten. So lässt sich mittels Scaling Policies das Skalierungsverhalten für Hoch- bzw. Herunterskalierung separat einstellen. Etwa wenn du Kubernetes Pods schnellstmöglich hochfahren lassen willst, der Abbau überflüssiger Pods aber in Erwartung weiterer Lastspitzen langsam stattfinden soll.
Ein weiteres nützliches Feature ist die Existenz der Eigenschaft StabilizationWindowSeconds, die eine Art Filter für Flapping, also stark und häufig wechselndes Verhalten der beobachteten Metriken, darstellt. Eine genauere Auseinandersetzung mit den Konfigurationsmöglichkeiten des HorizontalPodAutoscalers würde den Rahmen dieses Blogposts sprengen, stattdessen verweise ich einmal mehr auf die oben verlinkte offizielle Dokumentation.
Der VerticalPodAutoscaler ist noch in einer frühen Betaversion (momentan v0.13.0) und deswegen noch nicht in der offiziellen Kubernetes Dokumentation enthalten. Eine Auflistung seiner Fähigkeiten und Dokumentation findet sich im oben verlinkten Repository des Projekts.
Skalierung von Nodes
Hast du über einen längeren Zeitraum eine hohe Last auf deinem Cluster, und/oder wurden nach und nach immer mehr verschiedene Deployments hochskaliert, kann es passieren, dass die Nodes des Clusters selbst an die Grenzen ihrer Ressourcenkapazitäten zu gelangen. Auch hier hat man nun die Möglichkeit, horizontal oder vertikal zu skalieren, um das Cluster weiter funktionsfähig zu halten.
Für die horizontale Skalierung eines Kubernetes-Clusters stellt das Kubernetes-Projekt auf GitHub den Cluster-Scaler zur Verfügung, der in der Lage ist, dynamisch Nodes bei einer Vielzahl an Public-Cloud-Providern zu (de-)provisionieren.
Die vertikale Skalierung der Nodes eines Kubernetes-Clusters kann dir noch nicht durch einen Controller abgenommen werden – hier ist manuelle oder extern automatisierte Arbeit notwendig. Hast du also deine Kubernetes-Cluster auf VMs aufgesetzt, kannst du deren zugewiesene Ressourcen (vCPUs, Arbeitsspeicher, Festplattenspeicher) anpassen. Läuft Kubernetes als „Managed Kubernetes„, ist es oftmals möglich, die Node Pools anzupassen zu einer leistungsstärkeren Klasse an Nodes.
Fazit
Auf den ersten Blick erscheint die Skalierung von Workloads und des Clusters selbst, wie so viele Dinge rund um Kubernetes, als machbares Vorhaben. Dank kubectl und der von der API angebotenen Objekttypen in Kombination mit den vorhandenen Autoscalern können Workloads sowohl imperativ als auch deklarativ und horizontal sowie vertikal skaliert werden. Für Cluster in der Cloud lassen sich auch Nodes horizontal skalieren.
Geht man allerdings weiter ins Detail, findet man viele Stellschrauben, fortgeschrittene Konzepte und Designfragen, die es bei der Definition eines Autoscaler-Objekts zu beachten gilt. Hier ist die Erfahrung der zuständigen Clusteradministratoren gefragt, um die Kapazitäten des Clusters durch Autoscaling optimal zu nutzen, ohne Ressourcen unnötig zu verschwenden oder Workloads zu spät oder gar nicht zu skalieren.
Auch Monitoring der Workloads kann helfen, um nach und nach ein Gespür für zu erwartende Auslastung des Kubernetes-Clusters zu bekommen und das Autoscaling einiger oder gar aller Anwendungen im Cluster feinjustieren zu können.


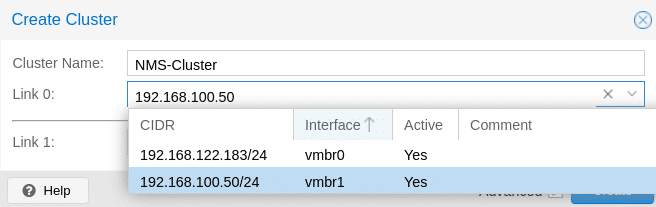
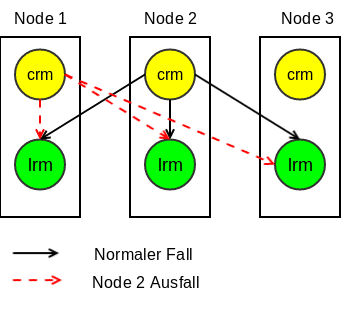 Man kann aus verschiedenen Nodes ein Cluster aufbauen, so dass die Hochverfügbarkeit der Gäste und Lastverteilung gesichert ist (mindestens 3 Nodes werden empfohlen). Pve-cluster ist der wichtigste Service im
Man kann aus verschiedenen Nodes ein Cluster aufbauen, so dass die Hochverfügbarkeit der Gäste und Lastverteilung gesichert ist (mindestens 3 Nodes werden empfohlen). Pve-cluster ist der wichtigste Service im