Let’s dive into the memories of stackconf 2023 together, which provided us with numerous insights and first-class expert knowledge. As part of this blog series, we would like to introduce you to the featured speakers and their presentations. Today – Paul Stack and his talk „It’s time to rebuild DevOps“ on how to inspire new tool development.
A short Summary
![]() Paul’s approach emphasizes the need to redefine DevOps tools to meet the original goals of the movement by breaking down existing silos and improving communication. The featured systems initiative presents a modern, simulation-based workflow that enables real-time, multiplayer and multimodal collaboration to increase productivity in infrastructure management.
Paul’s approach emphasizes the need to redefine DevOps tools to meet the original goals of the movement by breaking down existing silos and improving communication. The featured systems initiative presents a modern, simulation-based workflow that enables real-time, multiplayer and multimodal collaboration to increase productivity in infrastructure management.
Watch Paul’s Talk
Take a deep dive into Paul’s reflection from his long journey through DevOps-lessons. Explore his presentation video and his slides.
Stay tuned
Save the date for stackconf 2024, the first speakers are already online. Mark June 18 and 19 in your calendar. Secure your ticket and stay up to date by signing up for our newsletter!

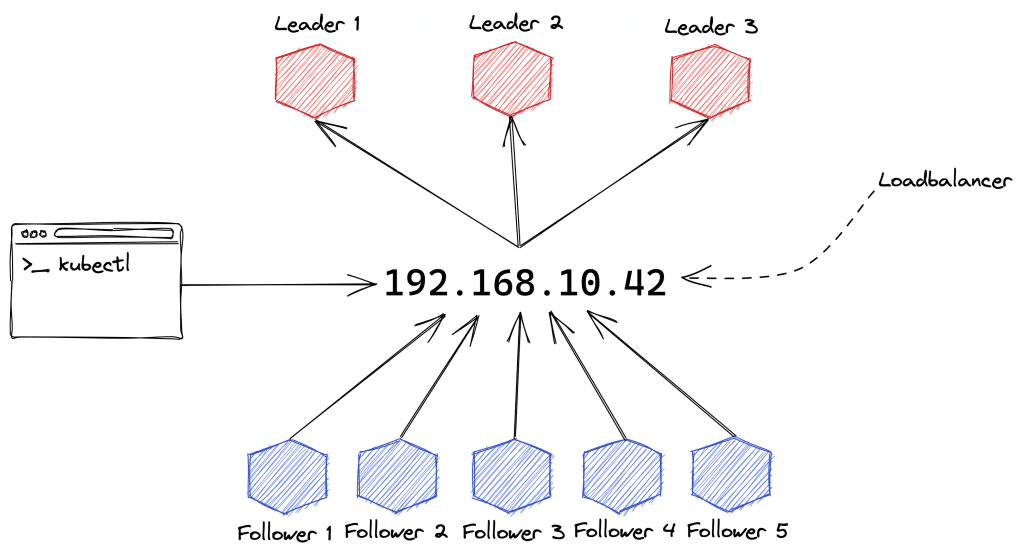
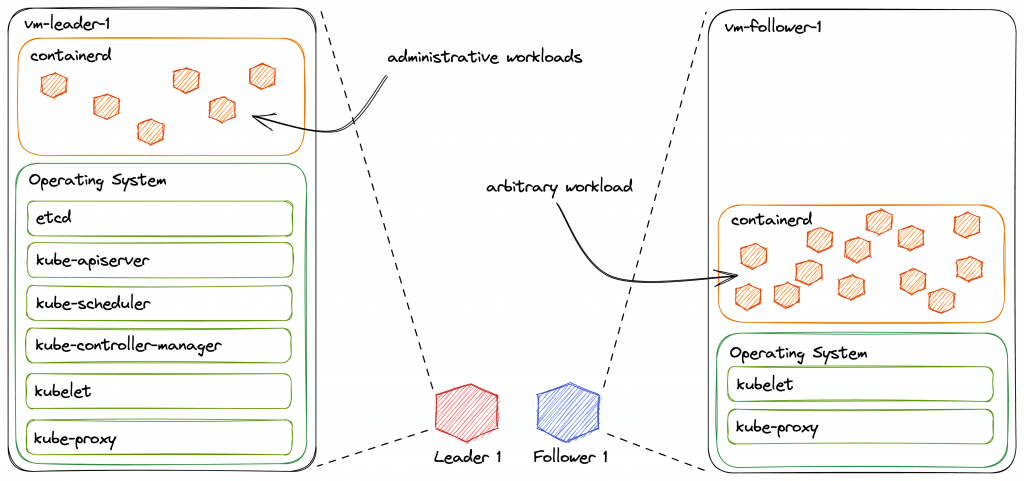

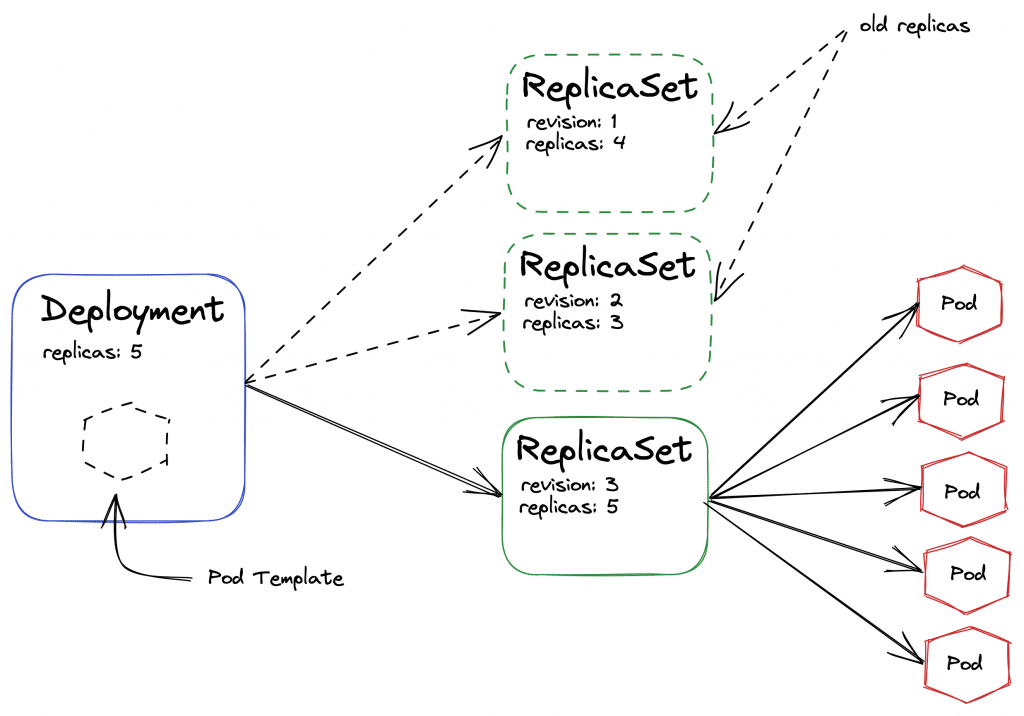
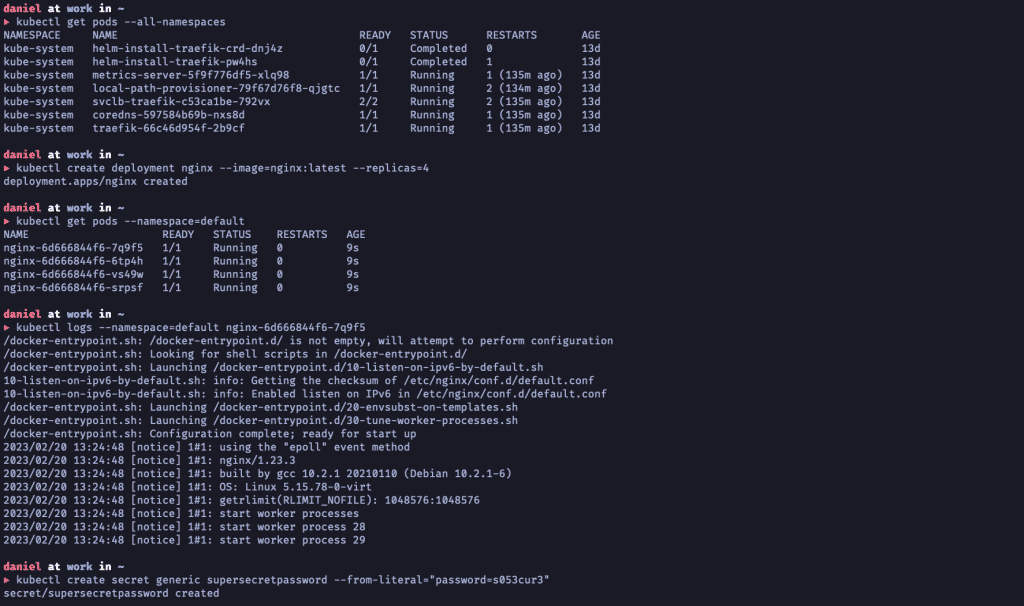



 Forms of provisioning
Forms of provisioning

















