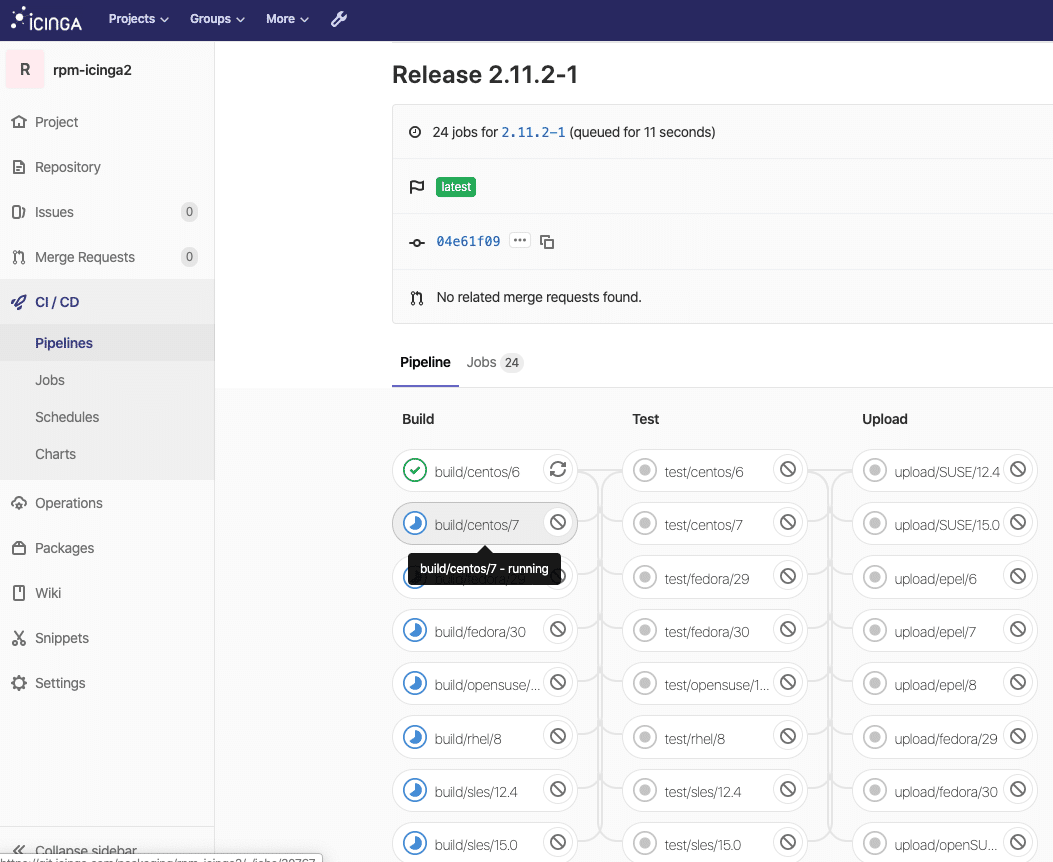
With migrating our CI/CD pipelines from Jenkins to GitLab CI in the past months, we’ve also looked into possible performance enhancements for binary package builds. GitLab and its CI functionality is really really great in this regard, and many things hide under the hood. Did you know that „Auto DevOps“ is just an example template for your CI/CD pipeline running in the cloud or your own Kubernetes cluster? But there’s more, the GitLab CI runners can run jobs in different environments with using different hypervisors and the power of docker-machine.
One of them is OpenStack available at NWS and ready to use. The following examples are from the Icinga production environment and help us on a daily basis to build, test and release Icinga products.
Preparations
Install the GitLab Runner on the GitLab instance or in a dedicated VM. Follow along in the docs where this is explained in detail. Install the docker-machine binary and inspect its option for creating a new machine.
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | sudo bash apt-get install -y gitlab-runner curl -L `uname -s`-`uname -m` -o /usr/local/bin/docker-machine chmod +x /usr/local/bin/docker-machine docker-machine create --driver openstack --help
Next, register the GitLab CI initially. Note: This is just to ensure that the runner is up and running in the GitLab admin interface. You’ll need to modify the configuration in a bit.
gitlab-runner register \ --non-interactive \ --url https://git.icinga.com/ \ --tag-list docker \ --registration-token SUPERSECRETKEKSI \ --name "docker-machine on OpenStack" \ --executor docker+machine \ --docker-image alpine
Docker Machine with OpenStack Deployment
Edit „/etc/gitlab-runner/config.toml“ and add/modify the „[[runners]]“ section entry for OpenStack and Docker Machine. Ensure that the MachineDriver, MachineName and MachineOptions match the requirements. Within „MachineOptions“, add the credentials, flavors, network settings just as with other deployment providers. All available options are explained in the documentation.
vim /etc/gitlab-runner/config.toml
[runners.machine]
IdleCount = 4
IdleTime = 3600
MaxBuilds = 100
MachineDriver = "openstack"
MachineName = "customer-%s"
MachineOptions = [
"openstack-auth-url=https://cloud.netways.de:5000/v3/",
"openstack-tenant-name=1234-openstack-customer",
"openstack-username=customer-login",
"openstack-password=sup3rS3cr3t4ndsup3rl0ng",
"openstack-flavor-name=s1.large",
"openstack-image-name=Debian 10.1",
"openstack-domain-name=default",
"openstack-net-name=customer-network",
"openstack-sec-groups="mine",
"openstack-ssh-user=debian",
"openstack-user-data-file=/etc/gitlab-runner/user-data",
"openstack-private-key-file=/etc/gitlab-runner/id_rsa",
"openstack-keypair-name=GitLab Runner"
]
The runners cache can be put onto S3 granted that you have this service available. NWS luckily provides S3 compatible object storage.
[runners.cache]
Type = "s3"
Shared = true
[runners.cache.s3]
ServerAddress = "s3provider.domain.localdomain"
AccessKey = "supersecretaccesskey"
SecretKey = "supersecretsecretkey"
BucketName = "openstack-gitlab-runner"
Bootstrap Docker in the OpenStack VM
Last but not least, these VMs need to be bootstrapped with Docker inside a small script. Check the „–engine-install-url“ parameter in the help output:
root@icinga-gitlab:/etc/gitlab-runner# docker-machine create --help ... --engine-install-url "https://get.docker.com" Custom URL to use for engine installation
You can use the official way of doing this, but putting this into a small script also allows customizations like QEMU used for Raspbian builds. Ensure that the script is available via HTTP e.g. from a dedicated GitLab repository 😉
#!/bin/sh
#
# This script helps us to prepare a Docker host for the build system
#
# It is used with Docker Machine to install Docker, plus addons
#
# See --engine-install-url at docker-machine create --help
set -e
run() {
(set -x; "$@")
}
echo "Installing Docker via get.docker.com"
run curl -LsS https://get.docker.com -o /tmp/get-docker.sh
run sh /tmp/get-docker.sh
echo "Installing QEMU and helpers"
run sudo apt-get update
run sudo apt-get install -y qemu-user-static binfmt-support
Once everything is up and running, the GitLab runners are ready to fire the jobs.
Auto-Scaling
Jobs and builds are not run all the time, and especially with cloud resources, this should be a cost-efficient thing. When building Icinga 2 for example, the 20+ different distribution jobs generate a usage peak. With the same resources assigned all the time, this would tremendously slow down the build and release times. In that case, it is desirable to automatically spin up more VMs with Docker and let the GitLab runner take care of distributing the jobs. On the other hand, auto-scaling should also shut down resources in idle times.
By default, one has 4 VMs assigned to the GitLab runner. These builds run non-privileged in Docker, the example below also shows another runner which can run privileged builds. This is needed for Docker-in-Docker to create Docker images and push them to GitLab’s container registry.
root@icinga-gitlab:~# docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS runner-privileged-icinga-1571900582-bed0b282 - openstack Running tcp://10.10.27.10:2376 v19.03.4 runner-privileged-icinga-1571903235-379e0601 - openstack Running tcp://10.10.27.11:2376 v19.03.4 runner-non-privileged-icinga-1571904408-5bb761b5 - openstack Running tcp://10.10.27.20:2376 v19.03.4 runner-non-privileged-icinga-1571904408-52b9bcc4 - openstack Running tcp://10.10.27.21:2376 v19.03.4 runner-non-privileged-icinga-1571904408-97bf8992 - openstack Running tcp://10.10.27.22:2376 v19.03.4 runner-non-privileged-icinga-1571904408-97bf8992 - openstack Running tcp://10.10.27.22:2376 v19.03.4
Once it detects a peak in the pending job pipeline, the runner is allowed to start additional VMs in OpenStack.
root@icinga-gitlab:~# docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS runner-privileged-icinga-1571900582-bed0b282 - openstack Running tcp://10.10.27.10:2376 v19.03.4 runner-privileged-icinga-1571903235-379e0601 - openstack Running tcp://10.10.27.11:2376 v19.03.4 runner-non-privileged-icinga-1571904408-5bb761b5 - openstack Running tcp://10.10.27.20:2376 v19.03.4 runner-non-privileged-icinga-1571904408-52b9bcc4 - openstack Running tcp://10.10.27.21:2376 v19.03.4 runner-non-privileged-icinga-1571904408-97bf8992 - openstack Running tcp://10.10.27.22:2376 v19.03.4 runner-non-privileged-icinga-1571904408-97bf8992 - openstack Running tcp://10.10.27.23:2376 v19.03.4 ... runner-non-privileged-icinga-1571904534-0661c396 - openstack Running tcp://10.10.27.24:2376 v19.03.4 runner-non-privileged-icinga-1571904543-6e9622fd - openstack Running tcp://10.10.27.25:2376 v19.03.4 runner-non-privileged-icinga-1571904549-c456e119 - openstack Running tcp://10.10.27.27:2376 v19.03.4 runner-non-privileged-icinga-1571904750-8f6b08c8 - openstack Running tcp://10.10.27.29:2376 v19.03.4
In order to achieve this setting, modify the runner configuration and increase the limit.
vim /etc/gitlab-runner/config.toml [[runners]] name = "docker-machine on OpenStack" limit = 24 output_limit = 20480 url = "https://git.icinga.com/" token = "supersecrettoken" executor = "docker+machine"
This would result in 24 OpenStack VMs after a while, and all are idle 24/7. In order to automatically decrease the deployed VMs, use the OffPeak settings. This also ensures that resources are available during workhours while spare time and weekend are considered „off peak“ with shutting down unneeded resources automatically.
OffPeakTimezone = "Europe/Berlin"
OffPeakIdleCount = 2
OffPeakIdleTime = 1800
OffPeakPeriods = [
"* * 0-8,22-23 * * mon-fri *",
"* * * * * sat,sun *"
]
Pretty neat functionality 🙂
Troubleshooting & Monitoring
„docker-machine ls“ provides the full overview and tells whenever e.g. a connection to OpenStack did not work, or if the VM is currently unavailable.
root@icinga-gitlab:~# docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS runner-privileged-icinga-1571900582-bed0b282 - openstack Error Unknown Expected HTTP response code [200 203] when accessing [GET https://cloud.netways.de:8774/v2.1/servers/], but got 404 instead
In case you have deleted the running VMs to start fresh, provisioning might take a while and the above can be a false positive. Check the OpenStack management interface to see whether the VMs booted correctly. You can also remove a VM with „docker-machine rm <id>“ and run „gitlab-runner restart“ to automatically provision it again.
Whenever the VM provisioning fails, a gentle look into the syslog (or runner log) unveils what’s the problem. Lately we had used a wrong OpenStack flavor configuration which was fixed after investigating in the logs.
Oct 18 07:08:48 3 icinga-gitlab gitlab-runner[30988]: #033[31;1mERROR: Error creating machine: Error in driver during machine creation: Unable to find flavor named 1234-customer-id-4-8#033[0;m #033[31;1mdriver#033[0;m=openstack #033[31;1mname#033[0;m=runner-non-privilegued-icinga-1571375325-3f8176c3 #033[31;1moperation#033[0;m=create
Monitoring your GitLab CI runners is key, and with the help of the REST API, this becomes a breeze with Icinga checks. You can inspect the runner state and notify everyone on-call whenever CI pipelines are stuck.
Conclusion
Developers depend on fast CI feedback these days, speeding up their workflow – make them move fast again. Admins need to understand their requirements, and everyone needs a deep-dive into GitLab and its possibilities. Join our training sessions for more practical exercises or immediately start playing in NWS!



 Zur Verwaltung von auf git basierenden Projekten bietet
Zur Verwaltung von auf git basierenden Projekten bietet 
















