Diese Woche wurde Graylog 5.2 veröffentlicht. Natürlich gibt es auch in diesem Release wieder Abstufungen für Open, Operations und Security.
Da wir nicht auf alles eingehen können, möchte ich hier auf die hervorzuhebenden Neuerungen und Änderungen eingehen. Ein vollständiges Changelog zum Release findet sich hier. Im Folgenden wollen wir auf zwei bemerkenswerte neue Features bzw. Änderungen im Detail eingehen.
HOT New Feature in Graylog OPEN/OPERATIONS/SECURITY: Pipeline Rule Builder UI
Der neue Pipeline Rule Builder UI ist wohl die auffälligste Neuerung und daher möchte ich darauf näher eingehen.
Das neue Pipeline Rule UI ist für all diejenigen hilfreich, die sich mit dem Schreiben von Pipeline Rule Code nicht auskennen oder sich noch nicht mit Pipeline Processing beschäftigt haben und daher Extraktoren am Input verwendet haben. Das neue UI (UserInterface) bringt hier eine ähnliche Handhabung wie bei den Extractoren. Die Extraktoren sind schon lange auf dem Weg aus dem Graylog heraus und sind und waren nie ein Weg für dynamische Verarbeitung.
Da dieses Menü bisher noch keine Erklärung gefunden hat, habe ich ein kurzes Video dazu gemacht. Vielleicht hilft das ja dem ein oder anderen von euch dies als Dokumentation zum verstehen.
Ausgangslage für das Video:
- TCP RAW Input auf Port 5114 mit statischem Feld „demo“ und dem Wert true
- rsyslog Daemon der im JSON Format sendet
- Pipeline und Stream für die Daten vorkonfiguriert.
Breaking Change in Graylog Security: lluminate Bundle
Dies sollte beachtet werden:
Die Verarbeitung von IP-Adressen zu Geo-IP-Informationen wurde aus dem Illuminate Bundle entfernt und benötigt nun den globalen „Geoip Resolver Processor“. Daher muss dieser aktiviert werden und dem „Illuminate Processor“ folgen. Dabei braucht ihr keine Angst haben, dass jetzt mehr Ressourcen verbraucht werden. Mittlerweile kann der Processor unterscheiden zwischen reserved und public IP. Zu dem könnt ihr ein „Enforce default Graylog schema“ aktivieren, dies sorgt dafür das nur Felder aufgelöst werden welche dem GIM entsprechen. Das sind folgende Felder:
- destination_ip
- destination_nat_ip
- event_observer_ip
- host_ip
- network_forwarded_ip
- source_ip
- source_nat_ip
Bedeutet aber auch das ihr diese Felder selbst auch bei anderen Applikation welche nicht im ILLUMINATE vorhanden sind entsprechend erzeugen müsst.
Wenn „Enforce default Graylog schema“ nicht aktiviert ist wird jedes Feld mit einer nicht reservierten IP-Addresse übersetzt.
Hierzu folgend die Einstellung für die Processor-Plugins welche notwendig sind:
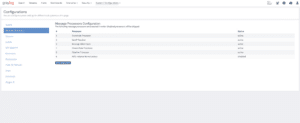
Graylog Processor configuration order and activation
Dazu muss dann entsprechend auch der Geo-IP Processor konfiguriert sein und die entsprechenden Informationsdatenbanken zum Beispiel von Maxmind auf allen Servern abgelegt sein.
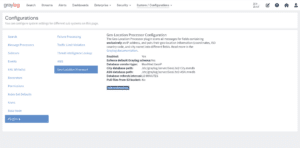
Alle weiteren Neuerungen und Änderungen in Graylog ILLUMINATE findet ihr hier.
Wir wünschen euch viel Spaß beim aktualisieren und Arbeiten mit den Neuerungen. Wenn ihr nicht weiter weißt oder Hilfe beim aktualisieren benötigt wir von NETWAYS Professional Services helfen euch gerne dabei. Meldet euch einfach bei unseren Sales TEAM!


















