Unternehmen können heutzutage gar nicht von Überwachungsmaßnahmen ihrer Umgebung entkommen, da wir als Menschen den aktuellen Stand von hunderten von Geräten nicht im Griff haben können. Deshalb werden Tools und Equipment im Überwachungsbereich dauernd entwickelt. Aus dem vorherigen erwähnten Bedarf möchte ich ein paar Informationen über zwei Geräte teilen und zwar AKCP sensorProbe2+ und SMSEagle.
AKCP sensorProbe2+
Das AKCP sensorProbe2+ ist ein Messgerät, an das verschiedene Arten von Sensoren angeschlossen werden können. Beispielhaft sind Bewegungs-, Gas-, Schall-, Temperatur, Feuchtigkeit- und Spannungssensoren. Stecken Sie einen beliebigen Sensor in die sensorProbe2+ und eine Autosense-Funktion erkennt den Typ und konfiguriert ihn automatisch. Standardmäßig hat das SP2+ die IP-Adresse 192.168.0.100. Es ist über einen Webbrowser konfigurierbar – sogar die IP-Adresse lässt sich ändern unter Einstellungen => IP-Einstellungen. Aber der angeschlossene PC muss im gleichen Netz wie der SP2+ sein, um die Verbindung herstellen zu können. Das Gerät kann in einem beliebigen Intervall sowohl seine Verfügbarkeit als auch sämtliche Messwerte durch SMS, Mail oder SNMP Trap mitteilen.
SMSEagle
SMSEagle ist ein SMS Gateway, das SMS und Mails schickt bzw. empfängt. Mails können in SMS umgewandelt werden und umgekehrt. Darüber hinaus gibt es eine eingebaute Überwachungsfunktion, die die Verfügbarkeit von Geräten und Ports überprüft (ICMP, SNMP, TCP, UDP) und beim Ausfall eine SMS oder Mail sendet. SMS können sogar weitergeleitet werden mit Nutzung von Filtern oder ohne. Zusätzlich können wir eine automatische Antwortregel konfigurieren. LDAP-Autentifizierung kommt auch als Feature mit.
Kombination von beiden Geräten:
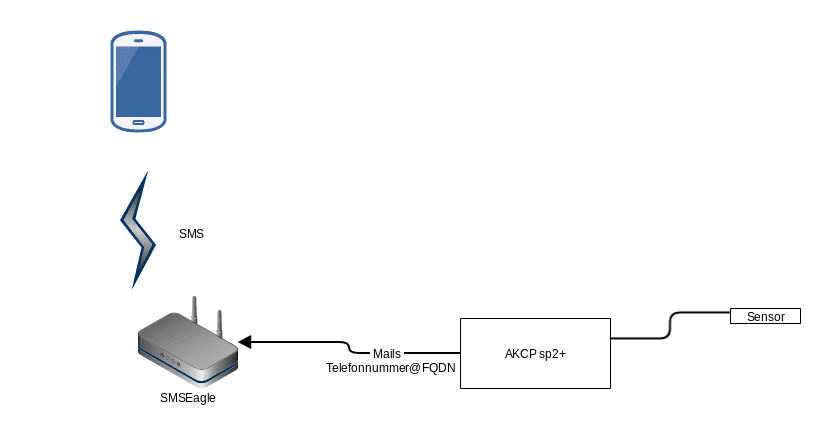
Beide Geräte müssen nicht im gleichen Netzwerk sein, sondern es reicht, wenn beide einander anhand von einem SMTP-Server sehen. SMSEagle besitzt sogar einen integrierten SMTP-Server, der dafür benutzt werden kann. Dessen IP-Adresse habe ich beim SP2+ eingetragen. SMSEagle akzeptiert nur Mails, die an ihn gesendet sind und lehnt den Rest ab. In SMSEagle muss „Mail to sms“ Plugin aktiviert werden, um eingehende Benachrichtigungsmails von SP2+ in SMS zu wandeln und an die gewünschte Nummer zu senden. Im SensorProbe2+ muss man eine Mail-Aktion unter Hauptmenü erstellen, in dem man Zieltelefonnumme@SMSEgale-FQDN als Zielmail einträgt. Zieltelefonnummer könnte man durch gespeicherte Kontaktnamen im Telefonbuch vom SMSEagle ersetzen, wenn es keine Leerzeichnen enthält. SP2+ akzeptiert nur FQDN als Zieladresse. Deswegen muss man folgende Konfigurationseinträge durchführen plus einen DNS-Eintrag für SMSEagle :
[ NXS Geräte unter]
/etc/postfix/main.cf
[NPE Geräte unter]
/mnt/nand-user/postfix/etc/postfix/main.cf
1. folgende Zeile finden „myhostname = localhost.localdomain“ und ändern in „myhostname = yourdomain.com“
2. Konfiguration von Postfix reloaden
postfix reload
Wir können eine Testmail von SP2+ schicken und im Eventslog nachschauen, ob sie versendet werden konnte , oder ob es eine Fehlermeldung gibt. Außerdem können wir unter „notification rules“ einstellen, bei welchem erreichten Schwellenwert eine Mail geschickt werden soll. Hier haben wir fünf einstellbare Schwellenwerte Normal, High Warning, High Critical, Low Warning und Low Critical. Wir können auf der anderen Seite in den Maillog von SMSEagle unter /etc/var/log/mail.info, in Systemlog oder unter Einstellungen => sysinfo nachschauen, ob die gesendeten Mails vom SP2+ angekommen sind und als SMS weitergeschickt wurden.
Man kann SP2+ mit Icinga 2 verbinden, wofür man lediglich das entsprechende Plugin benötigt: check_sensorProbe2plus
Ansonsten helfen wir bei Fragen rund um die Hardware von AKCP und SMSEagle gerne weiter – wir sind erreichbar per Mail oder telefonisch unter der 0911 92885-44. Wer uns gerne bei der Arbeit ein bisschen über die Schulter schauen oder den Shop und die angebotenen Produkte verfolgen möchte, kann uns seit kurzem auch auf Twitter folgen – über @NetwaysShop twittert das NETWAYS Shop Team!

 An diesen Satz muss ich immer denken, wenn es auf
An diesen Satz muss ich immer denken, wenn es auf 


















