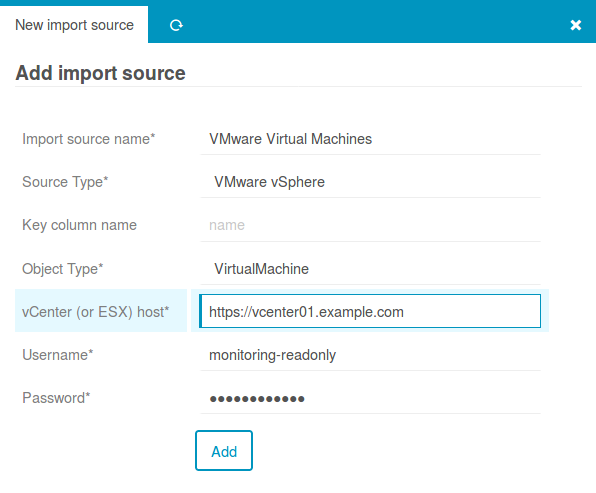
Es könnte so einfach sein. Auf der einen Seite eine Reihe von Import- und Sync-Definitionen welche aus den unterschiedlichsten Quellen unsere zu überwachenden CI’s importieren. Excel, CMDB, Datenbanken, AWS, JSON, YAML, LDAP, VMware, Active Directory – alles geht. Quellen werden kombiniert, Daten angereichert und wo nötig geradegebogen. Egal wie mies die Daten sind, der Director wird’s schon richten.
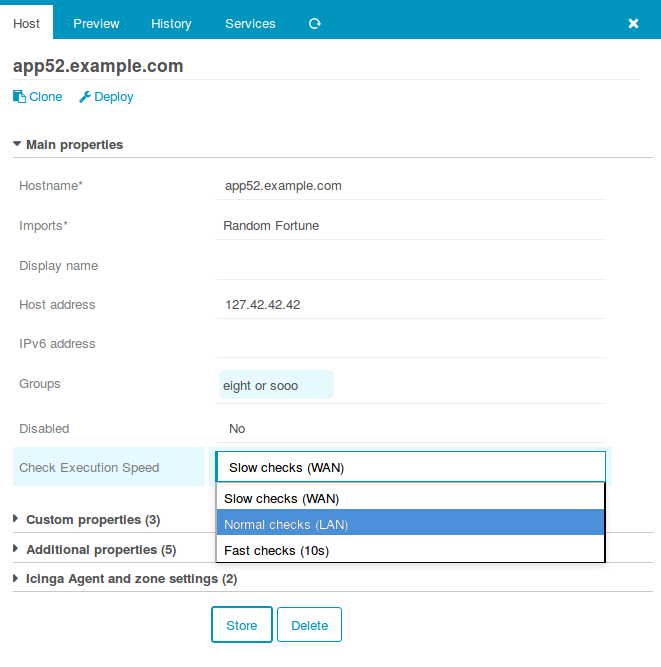
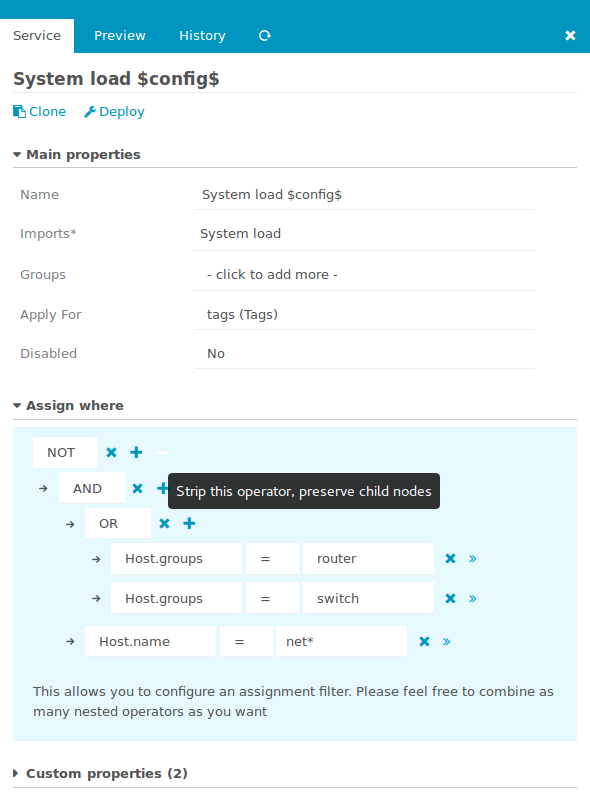
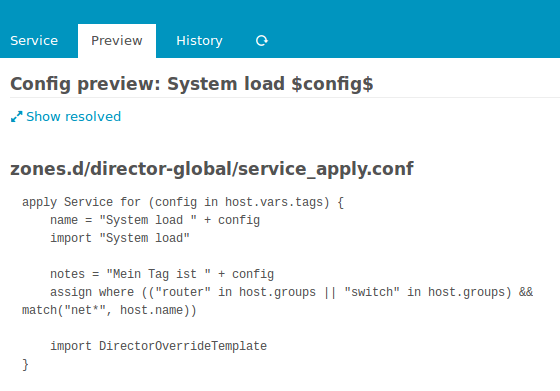
Auf der anderen Seite stehen mächtige Apply-Regeln. Diese weisen regelbasiert aus einem liebevoll vorbereiteten Service-Katalog das zu was passt. Ausnahmen von der Regel sind knifflig, nämlich dann wenn wöchentlich jemand wieder einen Schwellwert anders haben möchte. Genau dort wo wir’s nicht bedacht haben, dort wo Konstrukte mit vars am Host schnell hässlich werden.

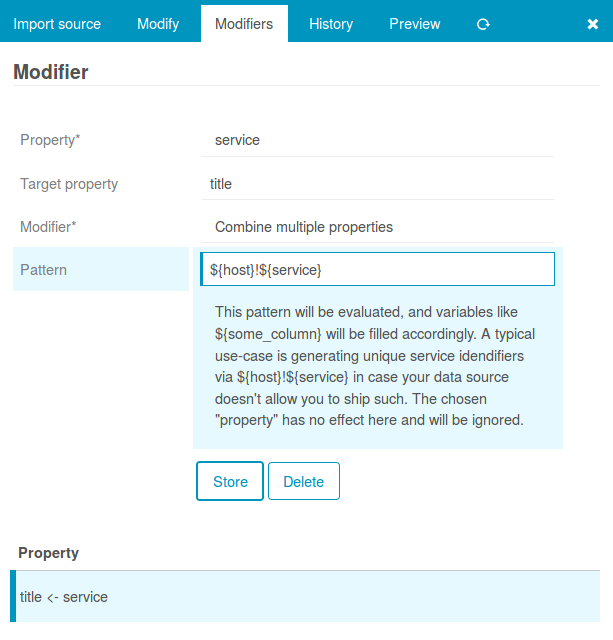
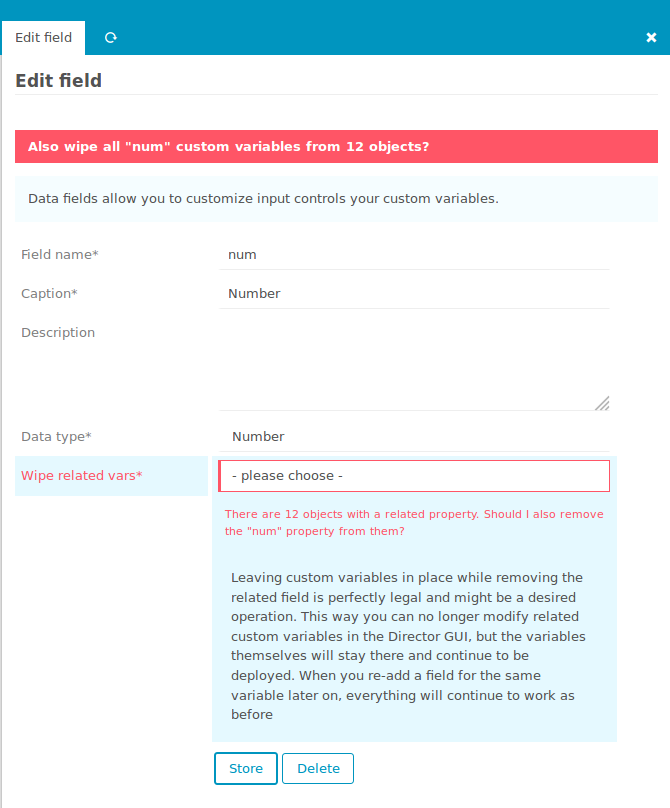
Auch hier hilft der Director, mit den „Custom Variable Overrides“ fühlt es sich so an als würde man wirklich diesem einen Service auf dem einen Host einen anderen Schwellwert verpassen. Alles gut soweit. Die Regeln sitzen, für Schwellwerte sind die Overrides da.

Nun ist unsere Welt aber leider nicht perfekt. Und das ist auch gut so, sonst wäre sie furchtbar langweilig. Für unsere Regeln bedeutet das leider, dass sie im Laufe der Zeit immer umfangreicher und komplizierter werden. Bis wir erneut an dem Punkt angelangen, an dem wir wieder am liebsten alles selbst machen würden. Wir haben nämlich Angst, dass es kaputt wird wenn es ein Kollege anpackt.
Klar, der Director hat ein wunderbares Aktivitätslog, man kann hinterher mit dem Finger auf eben diesen Kollegen zeigen und es heroisch selbst wieder geradebiegen. Ein Klick auf „Restore“ hilft dabei. Aber wenn man sich dann allein dadurch besser fühlt, dann hat man charakterlich durchaus noch Möglichkeiten an sich selbst zu arbeiten.
Zudem gab es vorher unnötigen Stress. Über zwei Wochen ist niemandem aufgefallen, dass die Checks für einen wichtigen Job auf ein paar Servern verschwunden sind. Am Wochenende ist das Ding an die Wand gerannt, das Monitoring blieb stumm. Bemerkt hat’s der Kunde, und wir mussten uns mal wieder so doofe Sprüche wie „Ja habt ihr denn kein Monitoring?“ anhören. Und alles nur, weil jemand mal wieder eine simple doppelte Verneinung falsch verstanden hat.
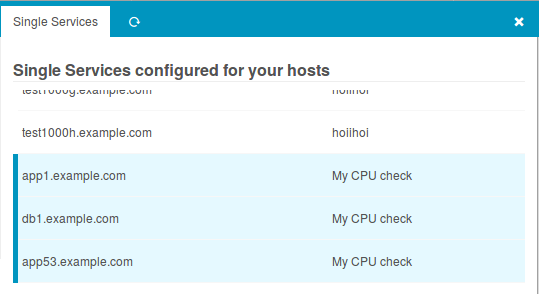
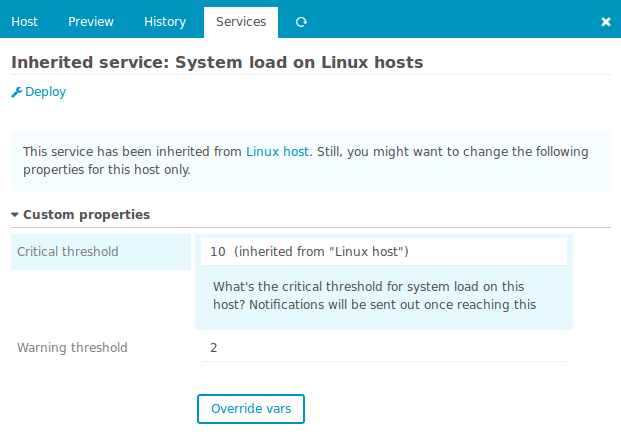
Mit dem Director v1.5.0 sind die häufigsten Ausnahmen von der Regel jetzt ein Kinderspiel. Man muss die Apply-Regel gar nicht mehr anfassen, einfach auf besagtem Host die Services anzeigen lassen, einen wählen, Blacklist, fertig:
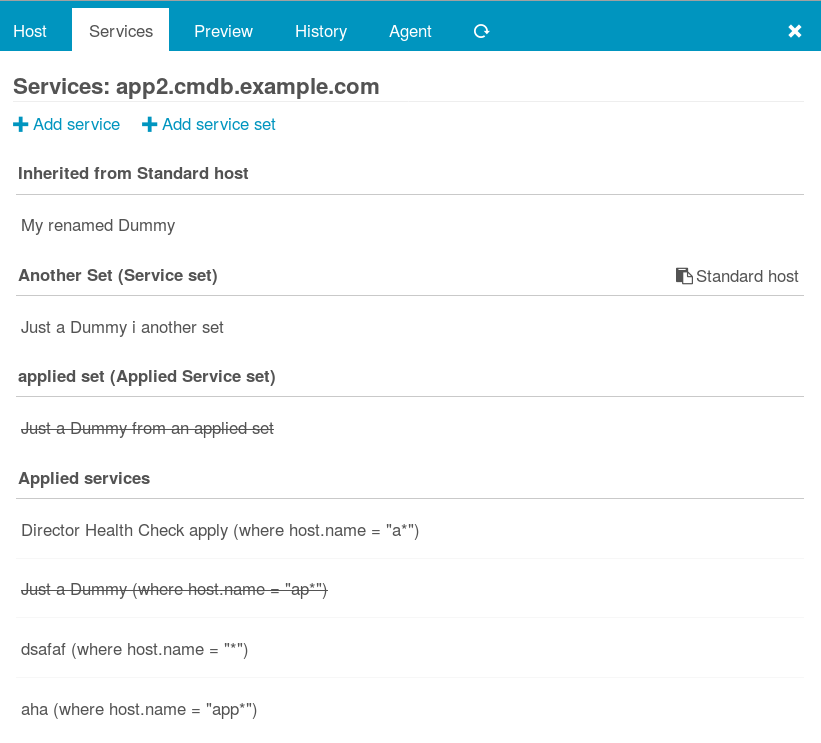
Im Hintergrund rendert der Director passende Ignore-Regeln und alles ist gut. Man kann wieder einen Task mehr an seine Kollegen delegieren und sich um Wichtigere Dinge kümmern. Also den Raspberry der den Wasserstand der Kaffeemaschine im Auge behält. Was in der v1.5.0 sonst noch alles neu ist steht im Release-Blogpost des Icinga-Blogs.