As the name suggests Todoist is an app for tracking todos. I’ve been using it for the past couple of months during which it has become a daily companion in my quest for getting things done without forgetting half of my stuff (which – if you know me – is a common occurrence).
The basic feature set is quite straight-forward: The app lets you create tasks which by default end up in the „Inbox“. Todoist has native apps for macOS, Windows, iOS and Android. There’s also a web client in case you need to update your tasks on-the-go. For me personally the integration with Amazon Echo is particularly useful. Adding a new task is as simple as saying „Alexa, add a task…“.
Once you’ve created a task you can decide to assign your tasks to a project (e.g. „Work“, „Personal“, etc.) either right away or later on when you have a few minutes to spare. Each task can also be tagged to make it easier to find groups of specific tasks. For example I have two tags „LowEnergy“ and „HighEnergy“ so I can later on find all tasks which are either easy or hard to do. Tasks can be set to re-occur at specific intervals which range in complexity from „daily“ to „every last friday“.
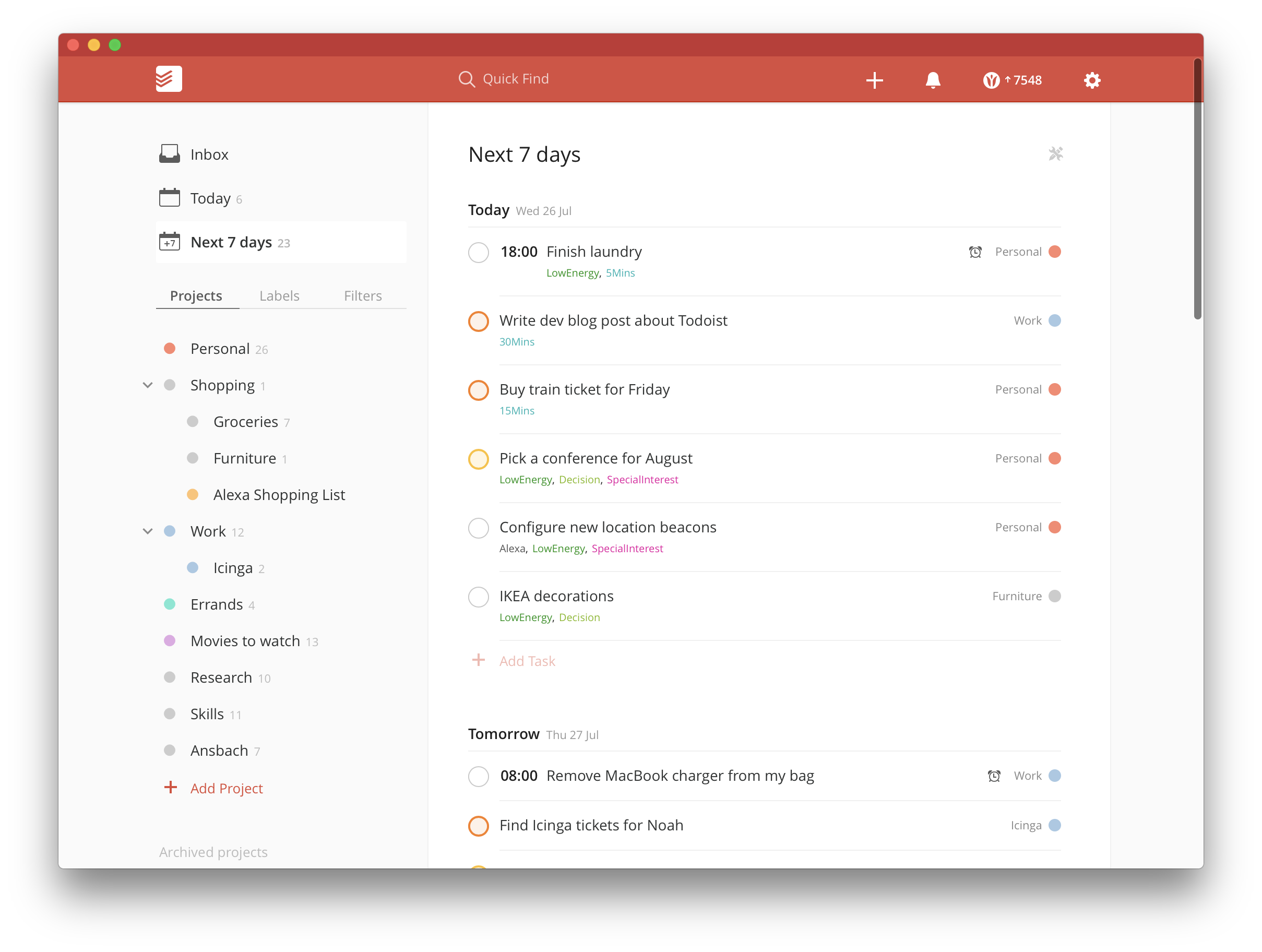
The mobile app supports location-based reminders. I have a recurring task „Get cash from the ATM“ which the app dutifully reminds me about when I pass the ATM on my way to work.
I wouldn’t go so far as to put Todoist in the „life saver“ category, however it has definitely become an integral part of my daily workflow. Consider giving it a try… even though unfortunately it isn’t entirely free.
NETWAYS Blog
Meine eigene TouchBar auf dem MacBook mit BetterTouchTool
Viele Anwendungen unterstützen leider noch nicht die TouchBar beim neuen MacBook Pro. Einige der „Schuldigen“ sind etwa Chrome, Radiant Player, Franz (ein Frontend für WhatsApp und andere Messaging-Apps). Zum Glück gibt es aber BetterTouchTool, mit dessen Hilfe man sich eigene Buttons auf die TouchBar konfigurieren kann:
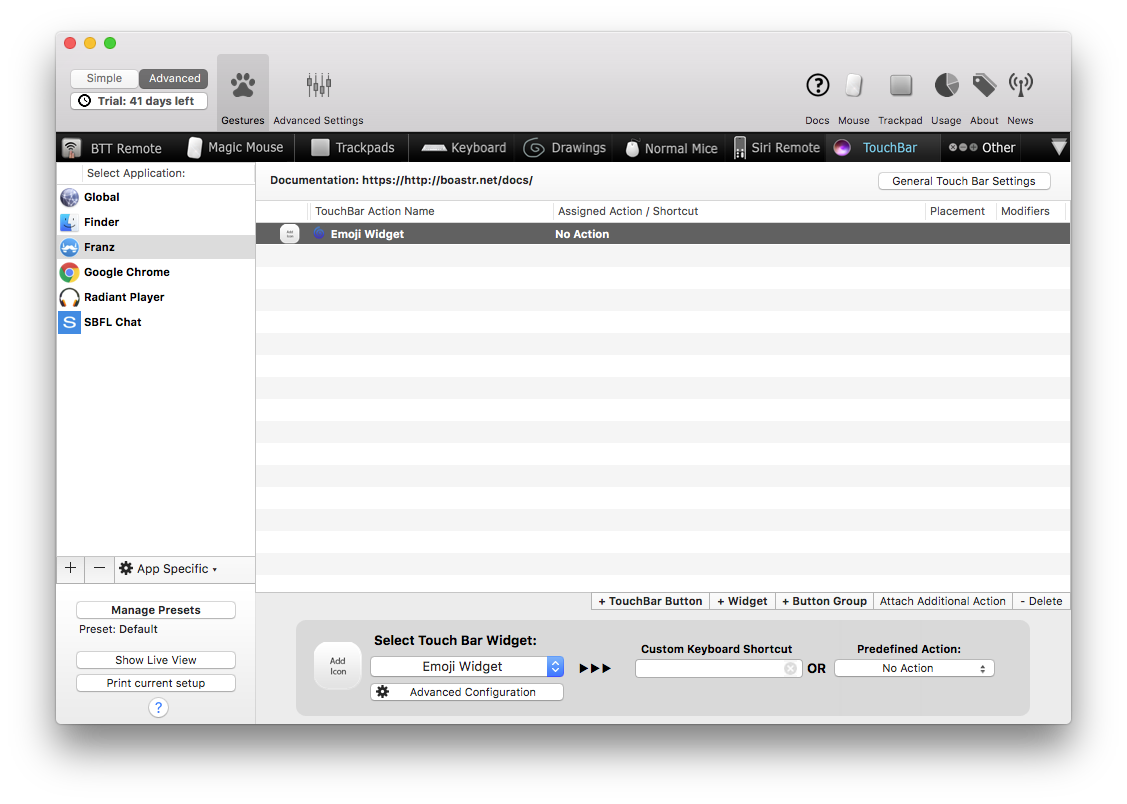
Leider ist sie dabei nicht kostenlos, aber bei meinen bisherigen Tests hat sie sich schonmal als sehr hilfreich erwiesen. Und so sieht das Beispiel oben dann auf der TouchBar aus:

BetterTouchTool kann dabei noch etliches mehr, beispielsweise:
- Lautstärke, Bildschirmhelligkeit, u.ä. regeln
- Benutzerdefinierte Scripts ausführen und deren Ergebnisse (als Text) auf der TouchBar anzeigen (z.B. aktueller Song)
- Eigene Gesten auf dem TrackPad erkennen
Location-Aware Settings With ControlPlane
Part of my „arriving at the office in the morning“ ritual involves quitting all my personal applications (e.g. Sonos), re-enabling my work e-mail account and a whole slew of other tiny changes that differentiate my work environment from my home environment. While in itself this isn’t too much of a hassle it does get rather tedious after a while. Especially so if I forget to start certain apps like my Jabber client and don’t realize that until much later.
The ControlPlane application promises to solve this exact problem by running specific actions whenever it detects a location change.
In order to do this you first have to set up „contexts“: These are essentially the locations you want ControlPlane to be aware of. As a starting point I’ve created two contexts „Home“ and „Work“ for my most-frequently used locations:
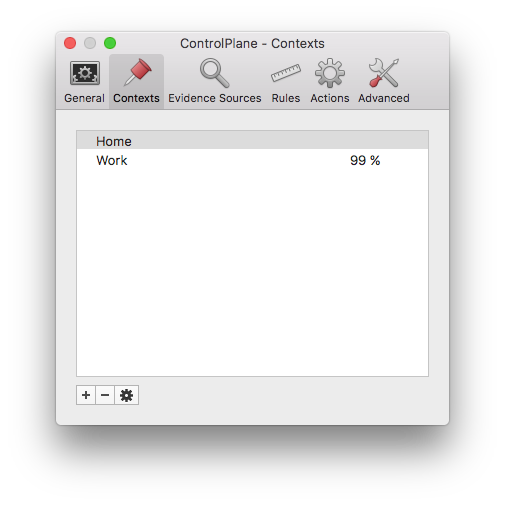
The next step involves telling ControlPlane what kind of information it should use to determine where you are. ControlPlane supports a wide variety of so-called evidence sources for this, some of which include:
- IP address range, nearby WiFi networks
- Attached devices (screens, USB and bluetooth devices)
- Bonjour services (e.g. AppleTV)
Once you’ve made up your mind about which evidence sources to use you need to actually configure rules for these sources. An example would be „If my laptop can see the WiFi network ’netways‘ I’m in the ‚Work‘ environment.“ You also get to choose a confidence rating for each of those rules. This is useful if some of your rules could potentially also match in other, unrelated environments – for example because the IP address range you’re using at work is also commonly used by other companies.
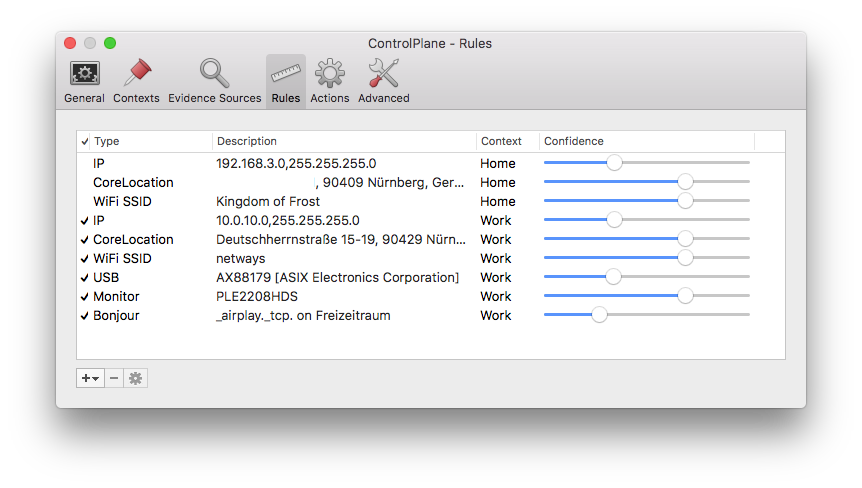
Once you’re sufficiently confident that your location detection rules are working reliably you can set up actions which ControlPlane automatically performs whenever you enter or leave a certain location:

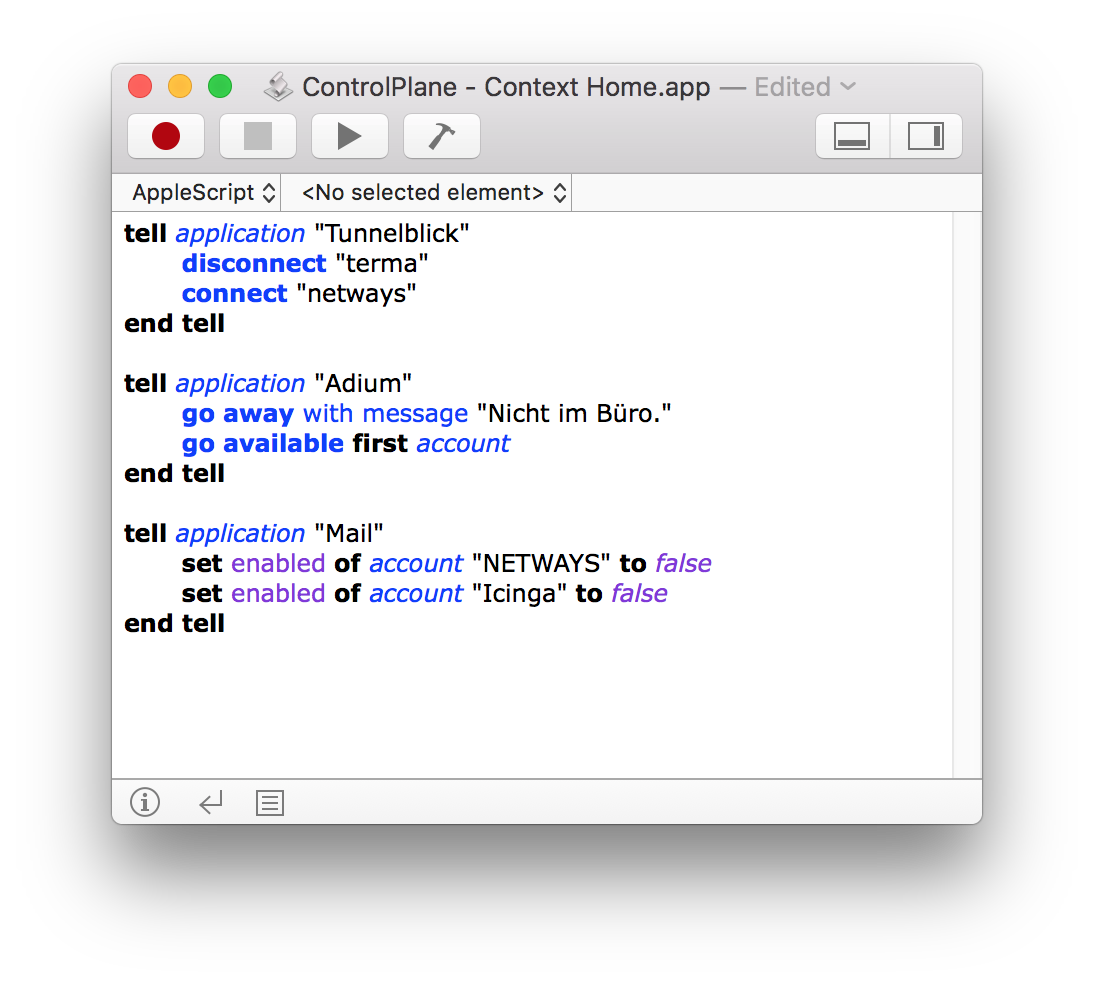
For my personal use I’ve found the built-in library of actions to be quite useful. However, there are a few things that even ControlPlane doesn’t support out of the box – like disabling specific e-mail and Jabber accounts. Luckily it does let you can run arbitrary external applications, including ones you’ve built with macOS’s Script Editor application:
Home Automation mit Home Assistant
Ich bin vor wenigen Wochen nach Nürnberg umgezogen, um mir die tägliche Zugfahrt von Ansbach her sparen zu können. Aber anstatt wie jeder andere vernünftige Mensch darauf zu schauen, dass Möbel in der Wohnung stehen, habe ich erstmal ein komplettes Wochenende damit verbracht, die Technik meines neuen Zuhauses soweit wie möglich zu automatisieren.
Seitdem mir ein Kollege (hallo Bernd!) schon vor einer ganzen Weile Home Assistant ans Herz gelegt hat, wollte ich dies ausprobieren, habe allerdings nie wirklich Zeit dafür gefunden. Beim Scrollen über 500 unterschiedliche Esszimmertische auf Amazon ändern sich aber die persönlichen Prioritäten ganz schlagartig und ich brauchte eine Abwechslung. Als Erstes habe ich mir in meinem persönlichen Datacenter (andere würden es als Abstellkammer bezeichnen) einen Linux-Container eingerichtet:
Als Hardware habe ich mir für das Projekt folgende Komponenten ausgesucht:
- Philips Hue Color (E27, dimmbar, bunt, toll)
- Philips Motion Detector (um die Lampen im Flur und Bad ansteuern zu können)
- Sonos PLAY:3 (in der Küche und auf meinem Schreibtisch), PLAY:5 (im Wohnzimmer)
- eQ-3 S 300 TH (Temperatur- und Feuchtigkeitssensor; inzwischen nicht mehr erhältlich, aber hatte ich zufälligerweise aus einem anderen Projekt übrig)
- iPhone (dient zur Erkennung, ob ich zu Hause bin)
- GAMMA-SCOUT Geigerzähler (braucht man unbedingt)
Und so sieht das ganze dann aus (inkl. strukturierter Verkabelung):
Ich werde hier niemanden mit der Config-Datei von Home Assistant langweilen, deswegen müsst ihr mir einfach glauben, wenn ich behaupte, dass es ein Kinderspiel ist, die einzelnen Hardware-Bausteine so darin zu integrieren, dass es ein sinnvolles Ganzes ergibt.
Besonders cool sind bei Home Assistant die Möglichkeiten, auf Events zu reagieren. So kann man beispielsweise abhängig vom Sonnenstand die Beleuchtung aktivieren bzw. deaktivieren. Meine Wohnung ist nun so eingestellt, dass automatisch alle Geräte ausgeschaltet werden, sobald ich das Haus verlasse. Wenn ich mich auf dem Weg nach Hause befinde, werden sie wieder eingeschaltet – kurz bevor ich tatsächlich an der Wohnungstür stehe. Dies funktioniert dadurch, dass Home Assistant über „Find my iPhone“ weiß, wo ich mich gerade befinde.
Natürlich gibt es dazu auch ein tolles Webinterface, über das man diese Aktionen steuern kann:
Zusätzliche habe ich mir von Happy Bubbles Bluetooth-Beacon-Detektoren bestellt, die hoffentlich im Laufe der nächsten Tage hier eintreffen werden. Danach sollte Home Assistant in der Lage sein, zu erkennen, in welchem Zimmer ich mich aktuell befinde.
Fazit: Nichts zu Essen im Haus – außer Joylent, aber die Beleuchtung lässt sich bis ins letzte Detail steuern. 🙂
Übrigens haben wir in unserem Shop auch Hardware, die sich in eigene Home Automation-Projekte integrieren ließe.
Icinga 2.6-Preview
Nächste Woche am Dienstag planen wir Icinga 2.6 zu releasen, quasi als vorgezogenes Weihnachtsgeschenk. Im Gegensatz zu den vorhergehenden „großen“ 2.x-Releases haben wir den Fokus diesmal nicht auf neue Features, sondern auf Bugfixes gesetzt.
Insbesondere haben wir etliche Bugs gefixt, die Notifications und den Cluster betreffen. So gibt es beispielsweise bis einschließlich Icinga 2.5.4 Bugs, die dafür sorgen, dass unter bestimmten Umständen Notifications fälschlicherweise versendet werden oder beim Synchronisieren des Clusters Objekte nicht richtig angelegt werden. Außerdem haben wir eine Reihe von Crashes gefixt, die wir mit Unterstützung unserer Kunden analysieren konnten.
Des Weiteren verwenden wir nun auch ausgewählte C++11-Features, um langfristig die Wartbarkeit des Projekts zu erhöhen. So sind in Icinga 2 nun z.B. range-based for loops „erlaubt“, die wir anstatt von BOOST_FOREACH verwenden. An ausgewählten Stellen verwenden wir auch das neue „auto“-Keyword, um Variablendeklarationen zu vereinfachen.
Zusätzlich haben wir das im Installer integrierte NSClient++-Paket auf die aktuelle Version (0.5.0) erneuert und für den Windows-Installer eingebaut, dass der Benutzer konfiguriert werden kann, mit dem Icinga gestartet wird.
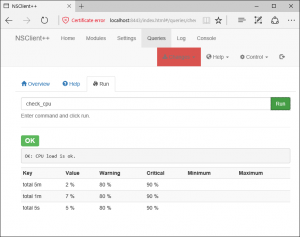
NSClient++ bietet seit Version 0.5.0 eine eigene REST-API, die wir zwar in der 2.6 noch nicht verwenden, aber bereits zum Ausprobieren von Commands sehr hilfreich ist:

Die Dokumentation ist nun an einigen Stellen deutlich ausführlicher und einfacher zu lesen: So wurde beispielsweise die Liste der globalen Funktionen in ein eigenes Kapitel umgewandelt.
Dank der Icinga-Community haben wir etliche Patches für die ITL integrieren können, die entweder neue CheckCommand-Definitionen liefern oder bereits vorhandene Commands erweitern. Für Kundenprojekte haben wir zudem selbst auch einige ITL-Erweiterungen eingebaut.
Um in absehbarer Zeit SELinux vollständig unterstützen zu können, verwendet Icinga 2.6 nun einen separaten Prozess, um Plugin-Checks zu starten. Dies ist notwendig, um genau steuern zu können, welche File-Deskriptoren an den Child-Prozess weitergegeben werden.
Insbesondere haben wir etliche Bugs gefixt, die Notifications und den Cluster betreffen. So gibt es beispielsweise bis einschließlich Icinga 2.5.4 Bugs, die dafür sorgen, dass unter bestimmten Umständen Notifications fälschlicherweise versendet werden oder beim Synchronisieren des Clusters Objekte nicht richtig angelegt werden. Außerdem haben wir eine Reihe von Crashes gefixt, die wir mit Unterstützung unserer Kunden analysieren konnten.
Des Weiteren verwenden wir nun auch ausgewählte C++11-Features, um langfristig die Wartbarkeit des Projekts zu erhöhen. So sind in Icinga 2 nun z.B. range-based for loops „erlaubt“, die wir anstatt von BOOST_FOREACH verwenden. An ausgewählten Stellen verwenden wir auch das neue „auto“-Keyword, um Variablendeklarationen zu vereinfachen.
Zusätzlich haben wir das im Installer integrierte NSClient++-Paket auf die aktuelle Version (0.5.0) erneuert und für den Windows-Installer eingebaut, dass der Benutzer konfiguriert werden kann, mit dem Icinga gestartet wird.
NSClient++ bietet seit Version 0.5.0 eine eigene REST-API, die wir zwar in der 2.6 noch nicht verwenden, aber bereits zum Ausprobieren von Commands sehr hilfreich ist:
Die Dokumentation ist nun an einigen Stellen deutlich ausführlicher und einfacher zu lesen: So wurde beispielsweise die Liste der globalen Funktionen in ein eigenes Kapitel umgewandelt.
Dank der Icinga-Community haben wir etliche Patches für die ITL integrieren können, die entweder neue CheckCommand-Definitionen liefern oder bereits vorhandene Commands erweitern. Für Kundenprojekte haben wir zudem selbst auch einige ITL-Erweiterungen eingebaut.
Um in absehbarer Zeit SELinux vollständig unterstützen zu können, verwendet Icinga 2.6 nun einen separaten Prozess, um Plugin-Checks zu starten. Dies ist notwendig, um genau steuern zu können, welche File-Deskriptoren an den Child-Prozess weitergegeben werden.
















