Als vor einer Weile unsere Catharina das neue Konzept für NETWAYS Chefs verkündet hat, hab ich sofort das Team „Zentrale Ausbildung“ für August eingetragen. Da zu dem Zeitpunkt eh ein gemeinsames Projekt anstand, war die Zeit dafür vorhanden und für mich ist es eine super Teambuilding-Maßnahme. Die Auszubildenden waren aus unterschiedlichen Gründen begeistert. Für die einen war es eine Chance, sich in der Küche auszutoben, für die anderen eine gratis Mahlzeit! 😉
Die ersten Ideen wurden immer mal wieder besprochen und es zeichnete sich schnell passend zum Sommer „Grillen“ als Thema ab. Die Pläne wurden dann am Ende der gemeinsamen Icinga-Schulung konkretisiert, sodass wir eine Umfrage für alle Kollegen erstellen konnten. Aus dieser durfte jeder ein oder zwei Hauptgerichte wählen. Wem nichts von unseren Vorschlägen gefallen hat, wählte die Option „You bring it, we grill it“. Beilagen in Form von Brot und Salaten versprachen wir einfach anhand der Anzahl von Kollegen beizusteuern. Und was wäre ein Essen ohne Nachtisch? Also sollten alle mit einem extra Magen für Süßes auch noch in dieser Spalte ein Kreuzchen machen. Nachdem sich bis zur Deadline fast 30 Kollegen eingetragen hatten, stand am Mittwoch der große Einkauf an. Hierfür legten wir gemeinsam fest, was gemacht werden sollte und wer dafür verantwortlich ist. Derjenige schrieb seine Zutaten zusammen und daraus machten unsere Einkäufer eine Liste. Als diese zurück waren, begannen schon die ersten Vorbereitungen, da manches über Nacht gehen, einziehen oder abkühlen sollte. Bevor wir aber nun mit den Rezepten starten, sollen nun erst mal unsere Einkäufer zu Wort kommen.
Der Einkauf von Johannes Rauh
Meine Aufgabe war es, die ganzen Einkäufe zu planen und durchzuführen. Diese Aufgabe habe ich mir mit Apostolos geteilt. Da wir schon den Nachmittag vor dem Grilltag angefangen hatten, die ersten Sachen vorzubereiten, mussten wir auch schon einen Tag davor einkaufen gehen. Dazu haben mir alle Leute ihre Rezepte mit genauen Mengenangaben geschickt und ich habe eine große Einkaufsliste zusammengeschrieben. Daraus hat sich ergeben, dass wir in 5 Läden mussten: Metzger, Baumarkt, einen griechischen Laden, ALDI und REWE.
Da wir ja Grillen wollten, war klar, dass wir eine gewisse Menge an Fleisch benötigen. Unsere Umfrage hat ergeben, dass wir 20 fränkische Bratwürste, 18 Putenspieße, 10 Rinder-Roastbeef à 200g, 10 Lachsfilets sowie 20 Grillkäse benötigen.
Alles bis auf die Lachsfilets wollten wir bei einem Metzger vorbestellen und am Tag des Grillens abholen. Hierfür sind wir zum Partyservice Wahler gefahren.
 Anschließend waren wir beim Baumarkt und haben die Gasflasche für unseren Gasgrill auffüllen lassen. So war sichergestellt, dass uns nicht plötzlich während des Grillens das Gas ausgeht und die Leute hungrig bleiben müssen.
Anschließend waren wir beim Baumarkt und haben die Gasflasche für unseren Gasgrill auffüllen lassen. So war sichergestellt, dass uns nicht plötzlich während des Grillens das Gas ausgeht und die Leute hungrig bleiben müssen.
Apostolos – ein Grieche durch und durch – hat darauf bestanden, den Joghurt für sein Tsatsiki in seinem griechischen Fachgeschäft des Vertrauens zu besorgen und so haben wir dort auch gleich ein Kilo Feta für die Salate geholt.
Der Plan für den Rest war, möglichst viel bei ALDI zu bekommen, um ein wenig Geld zu sparen. Alles, was wir dort nicht bekommen haben, haben wir vom REWE direkt nebenan geholt.
Fischmarinade von Dirk Götz
Irgendwann war mir danach, statt Fisch natur oder mit ein paar Kräutern gewürzt zu grillen, mich im Marinieren zu versuchen. Dabei bin ich über die „Fisch – Marinade à la Ralli“ auf Chefkoch gestolpert, die meine aktuelle Standard-Marinade geworden ist, aber wie immer mit ein bisschen Abwandlung.
Du brauchst:

1 TL Pfeffer (am besten bunter, frisch gemahlen)
1 TL Salz
1 Peperoni
1 EL süßer Senf
3 EL dunkle Sojasauce
12 EL Olivenöl
3 EL Balsamico
4 große Zehen Knoblauch
1/2 Bund Dill
So geht`s:
Die Peperoni einfach fein in Ringe schneiden, wobei ich persönlich Habanero oder ähnlich scharfe nehme, für die Kollegen sollte es aber eine einfache rote Peperoni tun. Den Dill fein hacken, alternativ geht auch getrockneter, aber frischer ist natürlich geschmacklich intensiver. Anschließend die Zutaten einfach vermengen.
Ich lasse den Fisch gerne über Nacht in der Marinade im Kühlschrank ziehen. Dafür einfach eine Schicht Fisch ins Gefäß legen, mit ein paar Löffeln Marinade übergießen, dann mit der nächsten Schicht wiederholen und zum Schluss den Rest einfach ins Gefäß gießen. Die Menge reicht für viel mehr als man denkt. Die 12 Lachsfilets waren also vollkommen ausreichend. Hat man weniger Zeit, kann man die Marinade auch während des Grillens immer wieder auftragen.
Mediterraner Kircherbsensalat von Dirk Götz
Bei diesem Salat handelt es um einen meiner Lieblingssalate zum Grillen. Dabei kann er aber auch ganz gut mit etwas Brot als vollwertige Mahlzeit dienen. Für die Kollegen hab ich die doppelte Portion gemacht, sodass auch genug für alle da war. Gefunden hab ich das Rezept auch wieder auf Chefkoch, da ich kein so großer Fan von Petersilie bin, lasse ich diese aber meist weg.
Du brauchst (für eine Schüssel):

1 Dose (800g) Kichererbsen
1 rote Zwiebel
1 Zucchini
1 (rote) Paprika
1 Peperoni
250g Feta (kann auch etwas mehr sein)
3 EL Balsamico-Essig
6 EL Olivenöl (und etwas zum Braten)
Zucker
Zitronensaft
Salz
So geht’s:
Die Kichererbsen abtropfen lassen. Währenddessen Essig, Öl, Zucker, Zitronensaft und Salz zu einem Dressing verrühren, wobei ich letztere nach Gefühl und durch Abschmecken dosiere. Die abgetropften Kichererbsen mit dem Dressing vermischen.
Die Zwiebel in schmale Halbkreise und die Peperoni in dünne Scheiben schneiden und hinzufügen. Auch hier darf es gerne eine schärfere Sorte sein, wenn man dies mag. Allerdings waren auch bei einer normalen Peperoni schon einige überrascht.
Zucchini in Scheiben und Paprika in feine Streifen oder größere Rechtecke schneiden und im Olivenöl anbraten. Das ganze darf schon etwas Farbe bekommen, die Zucchini gebräunt, die Paprika glasig.
Während des Anbratens den Schafskäse würfeln und unterheben. Nach dem Braten ebenso das Gemüse unterheben. Dabei lass ich auch gerne das Olivenöl vom Braten komplett mit reinlaufen. Gerne dann nochmal etwas abschmecken, je nach Geschmack braucht es noch etwas Zitronensaft oder Salz.
Mediterraner Nudelsalat mit getrockneten Tomaten und Pinienkernen von Leander Müller-Osten
Diesen Salat mach ich eigentlich bei jeder Grill-Feier. Zum einen ist er sehr schnell gemacht und auch sehr gut in großen Mengen zu machen. Vor allem heute, wo wir für ca. 25 Personen gekocht haben, genau der richtige Salat.
Du brauchst (für 10-12 Personen):

1kg Nudeln
1 Glas getrocknete Tomaten
400g Feta-Käse
2 Packungen Pinienkerne
4 EL Balsamicoessig
2 Becher Sauerrahm
3 Gläser rotes Pesto (grobes Pesto)
So geht’s:
- Bring einen Topf mit gesalzenem Wasser zum Kochen. Füge die Nudeln hinzu und koche sie gemäß den Anweisungen auf der Verpackung, bis sie al Dente sind.
- Rühre das Pesto nach Deinem Geschmack in die warmen Nudeln ein. Füge dann den Sauerrahm hinzu und vermische alles gut, bis die Nudeln gleichmäßig von der Pesto-Sauerrahm-Mischung umhüllt sind.
- Die getrockneten Tomaten abtropfen und in feine Streifen schneiden. Gib die geschnittenen Tomaten zu den Nudeln und rühre sie vorsichtig unter, damit sie sich gleichmäßig im Salat verteilen.
- Erhitze eine beschichtete Pfanne auf mittlerer Hitze. Gib die Pinienkerne in die Pfanne und röste sie leicht an, bis sie goldbraun und duftend sind. Achte darauf, sie regelmäßig zu wenden, damit sie sich gleichmäßig bräunen. Sobald die Pinienkerne fertig geröstet sind, nimm sie aus der Pfanne und gib sie zu den Nudeln.
- Zerbrösele den Fetakäse mit Deinen Händen über den Nudelsalat.
- Gib etwa 4 EL Balsamicoessig über den Salat. Nach Geschmack kannst Du auch etwas Olivenöl hinzufügen. Vermische alles gut und schmecke den Salat mit Salz und Pfeffer ab.
- Decke die Schüssel mit dem Nudelsalat ab und stelle sie für etwa 3-4 Stunden in den Kühlschrank.
Coleslaw von Leander Müller-Osten
Der Klassiker unter den Krautsalaten, der jedes Fleischgericht perfekt begleitet:
Du brauchst (für 10-12 Personen):

1 Kopf Weißkohl
1/2 Kopf Rotkohl
3 Karotten
3 Äpfel
Mayonnaise
Honig
Apfelessig
Senf (mittel scharf oder Dijon)
Selleriesamen
So geht’s:
- Kohl vorbereiten: Weißkohl und Rotkohl vierteln und den Strunk entfernen. Schneide den Kohl dann in möglichst dünne Streifen und gib ihn in eine große Schüssel.
- Entwässern des Kohls (optional, aber empfohlen): Um sicherzustellen, dass der Coleslaw knackig bleibt und nicht zu viel Wasser abgibt, füge 1-2 Teelöffel Salz zum Kohl hinzu und vermische alles gründlich. Etwa 1 Teelöffel Salz pro Kohlkopf sollte ausreichen. Lasse den Kohl mindestens eine halbe Stunde stehen. Du kannst auch etwas Schweres auf den Kohl legen, um das Wasser herauszudrücken. Drücke den Kohl nach dem Ruhen kräftig aus, um so viel Wasser wie möglich zu entfernen.
- Apfel und Karotte raspeln: Raspel die Äpfel und Karotten, um feine Raspeln zu erhalten. Die Apfel- und Karottenraspeln fügen dem Coleslaw eine angenehme Süße und zusätzliche Textur hinzu.
- Dressing anrühren: Bereite das Dressing vor, indem Du Mayonnaise, Honig, Apfelessig, Senf und Selleriesamen in einer separaten Schüssel vermengst. Die genauen Mengen hängen von Deinem persönlichen Geschmack ab, aber als Richtlinie könntest Du etwa 1/2 Tasse Mayonnaise, 1-2 Esslöffel Honig, 2-3 Esslöffel Apfelessig, 1 Teelöffel Senf und eine Prise Selleriesamen verwenden. Rühre alles gut um, bis das Dressing gleichmäßig vermischt ist.
- Alles zusammen mischen: Gib die geraspelten Äpfel und Karotten zum entwässerten Kohl in die Schüssel. Gieße das vorbereitete Dressing über die Zutaten und vermische alles gründlich, bis der Kohl, die Äpfel und die Karotten gut mit dem Dressing bedeckt sind.
- Kühlen: Decke die Schüssel mit dem Coleslaw ab und stelle sie in den Kühlschrank. Lasse den Coleslaw für mindestens 1 Stunde oder länger kühl stehen, damit sich die Aromen verbinden und der Coleslaw gut durchziehen kann.
Kartoffelsalat von Jan Schuppik
Kartoffelsalat ist ein zeitloser Favorit, der zu den unterschiedlichsten Anlässen passt. Egal, ob bei Grillfesten, als leichtes Sommeressen oder auf Buffets – dieser Klassiker erfreut sich stets großer Beliebtheit. Dieses Rezept verleiht dem traditionellen Kartoffelsalat eine erfrischende Note und stammt von Chefkoch. Er begeistert durch ein einzigartiges Geschmackserlebnis und eine aufmerksam durchdachte Zubereitung.
Du brauchst (für 10 Portionen)::

2,5 kg vorwiegend festkochende Kartoffeln
2,5 Zwiebeln, fein geschnitten
2,5 Tassen heiße Gemüsebrühe (ca. 125 ml pro Tasse)
5 EL Essig
7,5 EL Rapskernöl
2,5 TL Salz
Prise Pfeffer
1,25 Salatgurken
Senf und/oder Salatkräuter
So geht’s:
Beginne damit, die frisch gekochten Kartoffeln zu schälen und in handwarme, hauchdünne Scheiben zu schneiden. Lege die Scheiben in eine großzügige Schüssel.
Erhitze die Gemüsebrühe und gib den Essig hinzu. Diese Mischung wird dem Kartoffelsalat die perfekte, harmonische Note verleihen. Nach Belieben kann auch etwas Senf hinzufügt werden, dieser wird dann in der Brühe-Essig-Mischung aufgelöst.
Jetzt kommt der interessante Teil: Beginne mit einer Prise Salz über den Kartoffelscheiben, gefolgt von den fein geschnittenen Zwiebeln. Je nach Geschmack kannst Du eine Prise gemahlenen Pfeffer oder feine Salatkräuter hinzufügen. Gieße dann die heiße Brühe-Essig-Mischung über die Zutaten.
Als Nächstes füge das Rapskernöl hinzu, dieses ermöglicht eine gleichmäßige Verteilung der Aromen. Verwende zwei Esslöffel, um die Zutaten vorsichtig zu vermengen, bis alles gut durchmischt ist. Lasse den Salat für mindestens eine Stunde in der Wärme ruhen, damit die Aromen sich entfalten können.
 In der Zwischenzeit kannst Du die Salatgurken gründlich abwaschen und samt der Schale mithilfe eines Gemüsehobels in feine Scheiben schneiden. Diese knackige Ergänzung verleiht dem Salat eine erfrischende Textur und einen leichten Biss.
In der Zwischenzeit kannst Du die Salatgurken gründlich abwaschen und samt der Schale mithilfe eines Gemüsehobels in feine Scheiben schneiden. Diese knackige Ergänzung verleiht dem Salat eine erfrischende Textur und einen leichten Biss.
Sobald die Ruhezeit vorüber ist, füge die geschnittenen Gurkenscheiben hinzu und vermische alles behutsam miteinander.
Tipp:
Die heiße Gemüsebrühe in Kombination mit Essig mildert die Schärfe der Zwiebeln und lässt das Salz sowie den Pfeffer besser zur Geltung kommen. Das Öl wird immer zum Schluss hinzugefügt, um den Kartoffeln die Möglichkeit zu geben, Feuchtigkeit aufzunehmen und die Aromen gleichmäßig zu verteilen.
 In diesem ersten Teil ging es um das Grillgut und die Salate als Beilage. Im zweiten Teil kommen dann noch weitere Rezepte zu Broten, Dips und der Nachtisch dazu, denn wir wollten es uns natürlich richtig gut gehen lassen. Was auch schon das Abstimmungsergebnis gezeigt hat. 😉
In diesem ersten Teil ging es um das Grillgut und die Salate als Beilage. Im zweiten Teil kommen dann noch weitere Rezepte zu Broten, Dips und der Nachtisch dazu, denn wir wollten es uns natürlich richtig gut gehen lassen. Was auch schon das Abstimmungsergebnis gezeigt hat. 😉


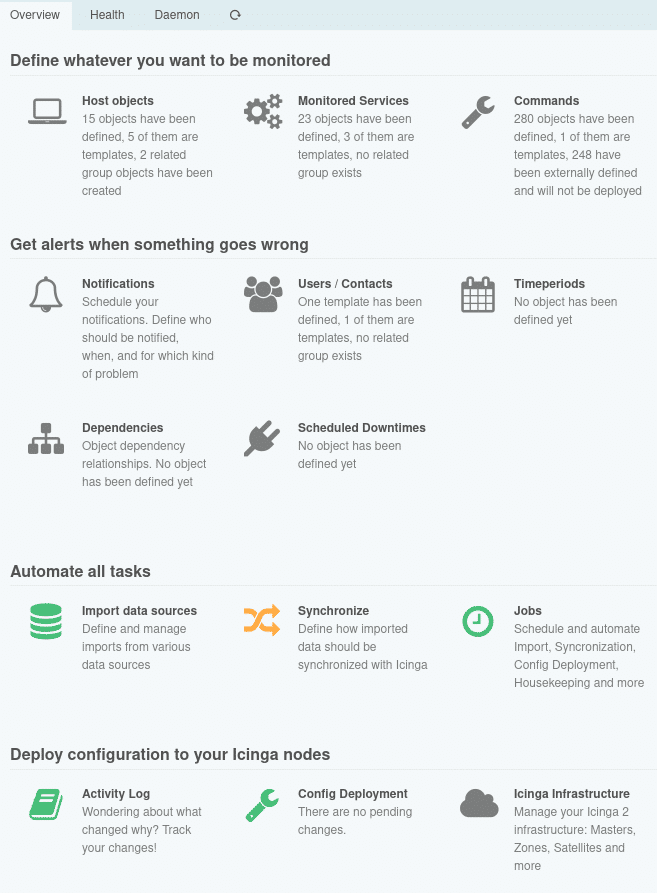 Der Icinga Director als grafisches Frontend zur Konfiguration stellt eine Abstraktion der Icinga DSL dar, denn es müssen natürlich für alle Objekte mit allen Attributen Eingabemasken existieren. Um das noch etwas klarer zu machen, gebe ich Dir einen kurzen Einblick in die Funktionsweise des Icinga Directors. Der Director importiert von einer Icinga-Instanz grundlegende Objekte wie Check-Kommandos, Endpunkte und Zonen. Nach diesem Kickstart musst Du für die allermeisten Objekte zunächst Templates anlegen, wobei direkt Felder für zusätzliche Eigenschaften zu erstellen und anzuhängen sind. Sobald Du auch konkrete Objekte angelegt hast, kannst Du die Konfiguration für Icinga rendern und über den entsprechenden API-Endpunkt produktiv nehmen.
Der Icinga Director als grafisches Frontend zur Konfiguration stellt eine Abstraktion der Icinga DSL dar, denn es müssen natürlich für alle Objekte mit allen Attributen Eingabemasken existieren. Um das noch etwas klarer zu machen, gebe ich Dir einen kurzen Einblick in die Funktionsweise des Icinga Directors. Der Director importiert von einer Icinga-Instanz grundlegende Objekte wie Check-Kommandos, Endpunkte und Zonen. Nach diesem Kickstart musst Du für die allermeisten Objekte zunächst Templates anlegen, wobei direkt Felder für zusätzliche Eigenschaften zu erstellen und anzuhängen sind. Sobald Du auch konkrete Objekte angelegt hast, kannst Du die Konfiguration für Icinga rendern und über den entsprechenden API-Endpunkt produktiv nehmen.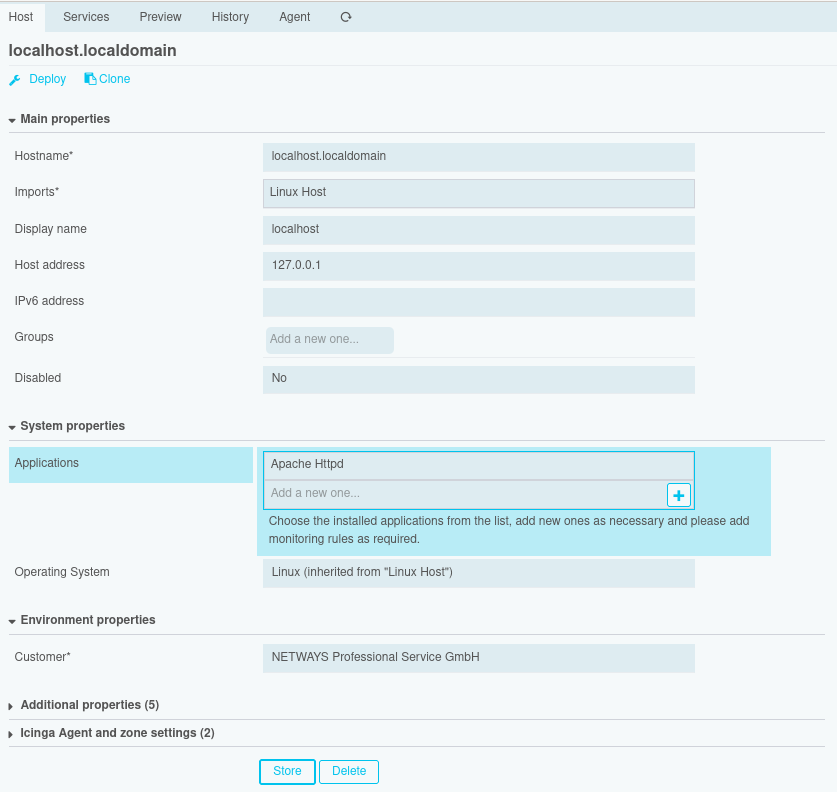 Auf der Trennung von Templates und Objekten baut auch das Rechtesystem des Directors auf, denn der Zwang zur Erstellung von Templates bereitet auch eine entsprechende Rollentrennung vor. So soll gewährleistet werden, dass ein Monitoring-Administrator ganz leicht Vorgaben machen kann und beispielsweise der Linux-Administrator anschließend einfach seine Hosts einpflegen braucht. Wer darauf geachtet hat, dem ist hier mein zögerliches Zugestehen aufgefallen. Denn ein Nachteil, den ich nicht verschweigen möchte, ist leider die Dokumentation des Directors. Alles Grundsätzliche ist in der Dokumentation durchaus enthalten. Manche Details jedoch werden erst durch Ausprobieren klar und Best Practices kristallisieren sich erst mit einiger Erfahrung heraus.
Auf der Trennung von Templates und Objekten baut auch das Rechtesystem des Directors auf, denn der Zwang zur Erstellung von Templates bereitet auch eine entsprechende Rollentrennung vor. So soll gewährleistet werden, dass ein Monitoring-Administrator ganz leicht Vorgaben machen kann und beispielsweise der Linux-Administrator anschließend einfach seine Hosts einpflegen braucht. Wer darauf geachtet hat, dem ist hier mein zögerliches Zugestehen aufgefallen. Denn ein Nachteil, den ich nicht verschweigen möchte, ist leider die Dokumentation des Directors. Alles Grundsätzliche ist in der Dokumentation durchaus enthalten. Manche Details jedoch werden erst durch Ausprobieren klar und Best Practices kristallisieren sich erst mit einiger Erfahrung heraus. Für mich ist schlussendlich meistens nicht entscheidend, wie einzelne Objekte konfiguriert werden können, da ich im Idealfall das Monitoring gar nicht manuell pflegen möchte. Und hier kommt eine der größten Stärken des Directors zum tragen: Der Director bietet die Möglichkeit, Daten aus einer Datenquelle zu importieren und aus diesen Daten dann Monitoring-Objekte zu erzeugen. Dabei können sogar noch Modifikatoren genutzt werden, um die Daten für den Verwendungszweck anzupassen.
Für mich ist schlussendlich meistens nicht entscheidend, wie einzelne Objekte konfiguriert werden können, da ich im Idealfall das Monitoring gar nicht manuell pflegen möchte. Und hier kommt eine der größten Stärken des Directors zum tragen: Der Director bietet die Möglichkeit, Daten aus einer Datenquelle zu importieren und aus diesen Daten dann Monitoring-Objekte zu erzeugen. Dabei können sogar noch Modifikatoren genutzt werden, um die Daten für den Verwendungszweck anzupassen.















