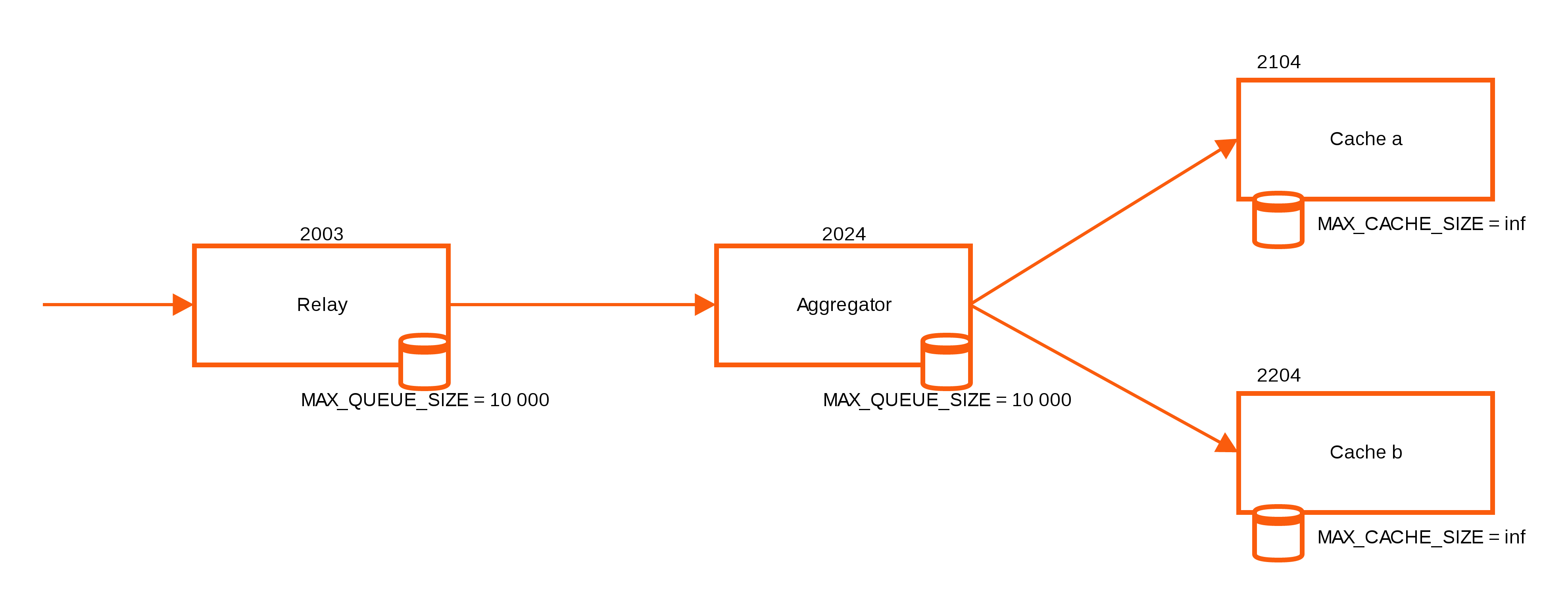
![]() Ich habe mich in der Vergangenheit mit verschiedenen Tools beschäftigt die Performancedaten bzw. Metriken speichern und darstellen können. Aktuell beschäftige ich mich näher mit Timelion aus dem Hause Elastic und das hat zwei Gründe: Zum einen wurde mir die Kibana Erweiterung auf der ElasticON letzte Woche wieder schmackhaft gemacht, nachdem ich es eigentlich schon zur Seite gelegt hatte. Zum anderen erweist sich Timelion als sehr nützlich in Verbindung mit meinem Icingabeat. Ein Beat der Daten aus Icinga 2 zur weiteren Verarbeitung entweder an Logstash oder direkt an Elasticsearch schicken kann.
Ich habe mich in der Vergangenheit mit verschiedenen Tools beschäftigt die Performancedaten bzw. Metriken speichern und darstellen können. Aktuell beschäftige ich mich näher mit Timelion aus dem Hause Elastic und das hat zwei Gründe: Zum einen wurde mir die Kibana Erweiterung auf der ElasticON letzte Woche wieder schmackhaft gemacht, nachdem ich es eigentlich schon zur Seite gelegt hatte. Zum anderen erweist sich Timelion als sehr nützlich in Verbindung mit meinem Icingabeat. Ein Beat der Daten aus Icinga 2 zur weiteren Verarbeitung entweder an Logstash oder direkt an Elasticsearch schicken kann.
Timelion, übrigens Timeline ausgesprochen, ist eine Erweiterung für das bereits bekannte Kibana Webinterface. Es ist dazu gedacht Daten aus einem Elasticsearch Cluster visuell darzustellen. Anders als die bisherigen Visualisierugsmethoden von Kibana wird bei Timelion aber nichts zusammen geklickt und gefiltert. Stattdessen müssen die eingebauten Funktionen direkt aufgerufen und mit Parametern gefüllt werden. Klingt erst mal kompliziert, nach etwas Übung geht das aber schneller als alles mit der Maus zu bedienen.
Ein Beispiel: Um die Anzahl der Dokumente in Elasticsearch zu zählen, wird die Funktion es() verwendet. Sie erwartet als Parameter eine Query. Mit es(*) werden sämtliche Dokumente gezählt, die Query dabei ist *
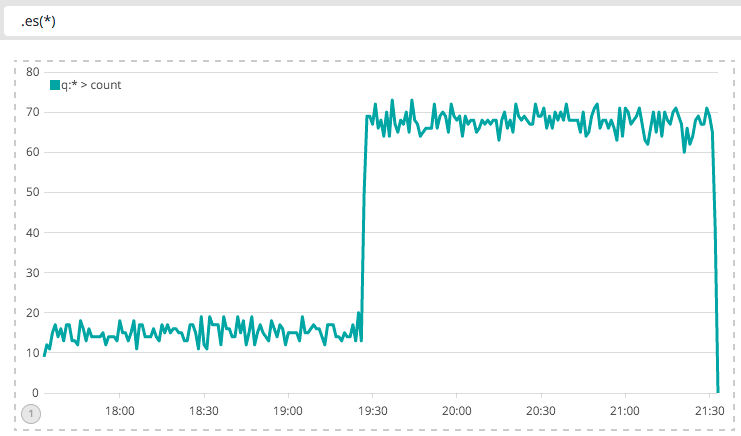
Als Query kann alles eingegeben werden was das normale Kibana Interface auch versteht, also Apache Lucene Syntax. Zum Beispiel kann ich die Anzahl der Checkresults darstellen, die mein Icinga gerade ausführt: .es(type:icingabeat.event.checkresult)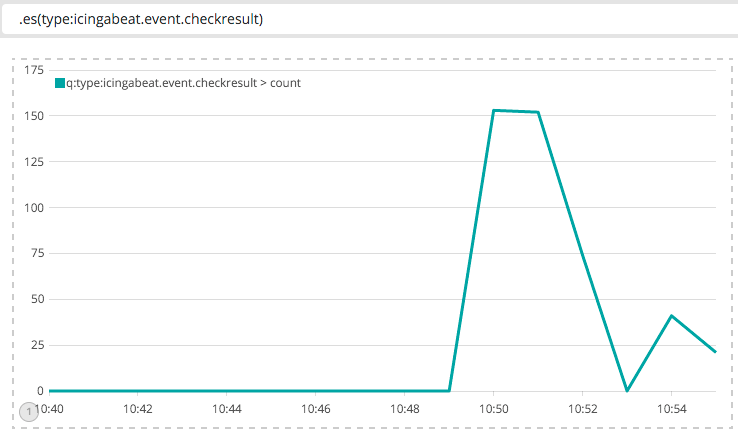
Einfach Dokumente zu zählen reicht aber oft nicht aus, insbesondere im Hinblick auf Metriken. Wichtig an dieser Stelle ist der eigentliche Wert von einem Eintrag, nicht die Anzahl der Einträge. Die es() Funktion kann mit ihrem metric Parameter genau das tun. Man muss sich lediglich entscheiden mit welcher Methode man die Daten aggregieren möchte. Auch wenn die Daten nicht in einem definierten Zeitrahmen in Elasticsearch gespeichert werden, müssen sie spätestens bei der Darstellung irgendwie zusammengefasst werden um einen gleichmäßigen Graphen anzeigen zu können. Timelion versucht den Abstand in dem Daten aggregiert werden automatisch zu ermitteln, meistens ergibt das „Sekündlich“. Ob das der richtige Intervall ist, hängt davon ab wie schnell die Daten rein fließen. Wie viele MySQL Queries Icinga 2 innerhalb der letzten Minute ausgeführt hat, lässt sich zum Beispiel folgendermaßen ermitteln:
.es(metric=avg:perfdata.idomysqlconnection_ido-mysql_queries_1min.value).label("1 min").title("MySQL Queries").color(green)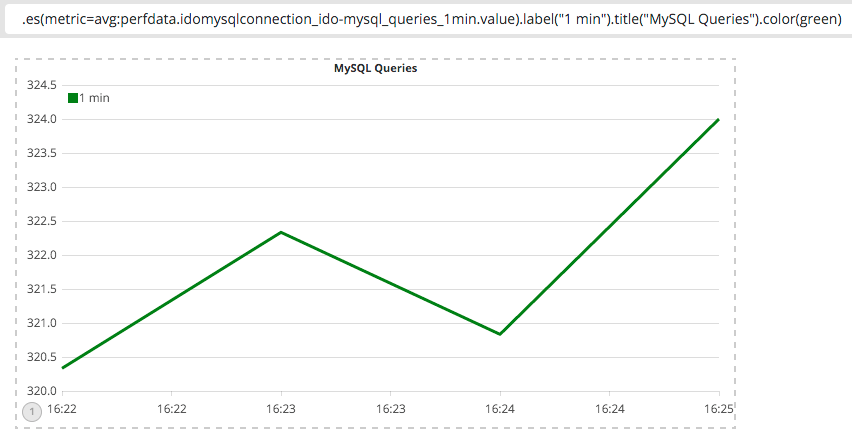
Hier sieht man auch das sich mehrere Funkionen aneinander ketten lassen. Zum Beispiel zum setzen von Titel oder Farbe. Timelion bringt eine ganze Fülle an Funktionen mit die die Darstellung der Daten beeinflussen. Ich will nicht alle aufzählen, weitere Beispiele aber sind:
bars(): Ein Barchart anstelle einer Liniemovingaverage(): Berechnet den gleitenden Durchschnittmin(),max()undsum(): Erklärt sich von selbst
Es können auch mehrere Linien innerhalb eines Graphen angezeigt werden, dazu wird die Funktion einfach mehrfach aufgerufen. Hier ein vergleich der Ausführungszeiten von Icinga Plugins:
.es(metric=avg:status.avg_execution_time), .es(metric=avg:status.max_execution_time), .es(metric=avg:status.min_execution_time) 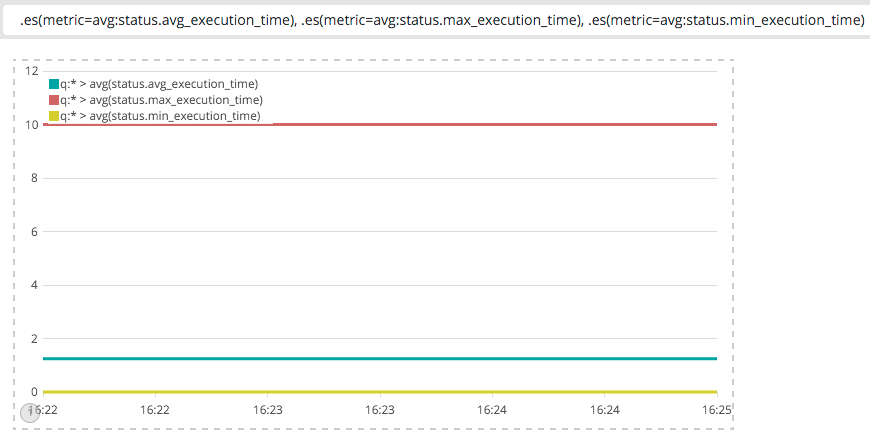
Insgesamt ist das nur ein kleiner Teil dessen was Timelion kann. Auch wenn die Bedienung etwas gewöhnungsbedürftig ist, so kommt man nach etwas Übung schnell rein. Die Graphen die erstellt werden können entweder als eigenständige Dashboards abgespeichert werden oder als einzelne Visualisierungen. Werden die Graphen einzeln abgespeichert können Sie zu Kibana Dashboards hinzugefügt werden. Dadurch ergibt sich eine gute Ergänzung zu den normalen Visualisierungen.